
GPTDAOCN-e/acc on Nostr: 揭秘Transformer模型的核心奥秘! ...
揭秘Transformer模型的核心奥秘!
这张图简化展示了Transformer模型的结构和工作流程:
1. Tokenizer(分词器):将文本分解为更小的单元(tokens),并转换为数值表示,以便后续处理。
2. Embedding(嵌入层):将分词后的tokens转换为向量,捕捉每个词的语义和上下文信息。
3. Positional Encoding(位置编码):为每个向量添加位置信息,以确保模型理解词语在句子中的相对位置。
4. Self Attention(自注意力机制):
- 在Encoder和Decoder中都应用。
- 计算句子中每个词对其他词的关注程度,理解其关系和上下文。
5. Output(输出层):处理后的数据被转化为适合任务需求的输出,例如分类或文本生成。
通过这些步骤,Transformer模型能够有效捕捉和理解复杂的语言模式,实现高效的自然语言处理。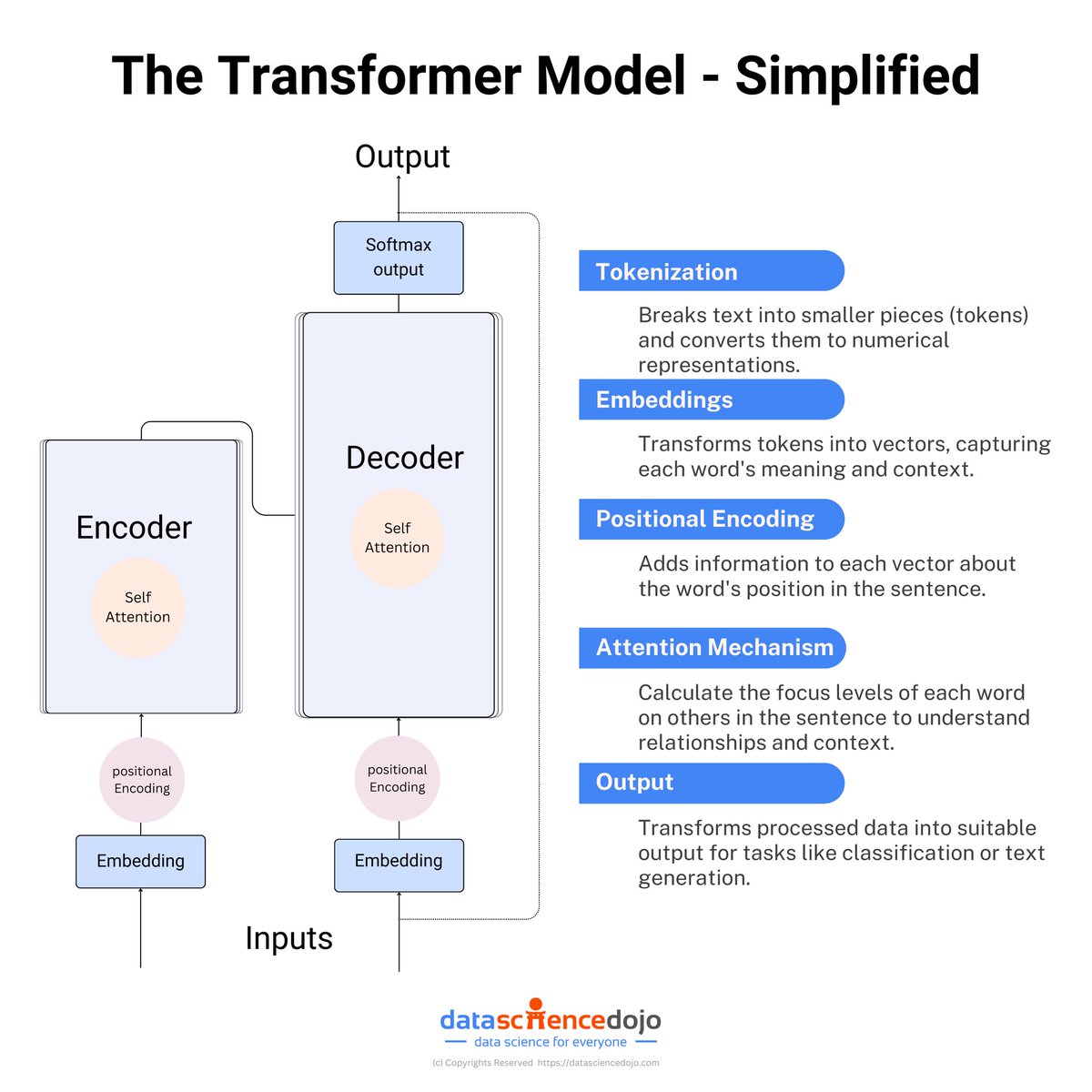
这张图简化展示了Transformer模型的结构和工作流程:
1. Tokenizer(分词器):将文本分解为更小的单元(tokens),并转换为数值表示,以便后续处理。
2. Embedding(嵌入层):将分词后的tokens转换为向量,捕捉每个词的语义和上下文信息。
3. Positional Encoding(位置编码):为每个向量添加位置信息,以确保模型理解词语在句子中的相对位置。
4. Self Attention(自注意力机制):
- 在Encoder和Decoder中都应用。
- 计算句子中每个词对其他词的关注程度,理解其关系和上下文。
5. Output(输出层):处理后的数据被转化为适合任务需求的输出,例如分类或文本生成。
通过这些步骤,Transformer模型能够有效捕捉和理解复杂的语言模式,实现高效的自然语言处理。