
GPTDAOCN-e/acc on Nostr: ...
Ķ┐ÖÕ╝ĀÕøŠÕ▒Ģńż║õ║åÕ”éõĮĢÕł®ńö©Õ╝║Õī¢ÕŁ”õ╣Ā’╝łRL’╝ēµØźĶć¬ÕŖ©õ╝śÕī¢ńö¤µłÉÕ╝ÅĶ»ŁĶ©Ćµ©ĪÕ×ŗ’╝łLLM’╝ēńÜäµÅÉńż║’╝łPrompt’╝ē’╝īõ╗źÕó×Õ╝║ÕģČÕ£©ńē╣Õ«Üõ╗╗ÕŖĪõĖŖńÜäĶĪ©ńÄ░ŃĆéĶ┐Öń¦Źµ¢╣µ│ĢõĖ╗Ķ”üķĆÜĶ┐ćõĖŹµ¢ŁĶ░āµĢ┤ÕÆīĶ»äõ╝░µÅÉńż║ńÜäµĢłµ×£µØźÕ«×ńÄ░’╝īÕøŠõĖŁÕīģÕɽÕćĀõĖ¬Õģ│ķö«ķā©Õłå’╝Ü
1. µĄüń©ŗµ”éĶ┐░
- ńö¤µłÉÕĆÖķĆēµÅÉńż║’╝ÜÕĘ”õŠ¦ÕøŠńż║õĖŁ’╝īDecoder-Onlyµ×ȵ×ä’╝łÕ”éGPTń▒╗µ©ĪÕ×ŗ’╝ēÕ£©µ»ÅõĖ¬µŚČķŚ┤µŁź’╝łTime Step’╝ēńö¤µłÉõĖĆõĖ¬ÕĆÖķĆēµÅÉńż║’╝īķĆɵŁźµ×äÕ╗║ÕÅ»ĶāĮµ£ēµĢłńÜäµÅÉńż║ÕåģÕ«╣ŃĆé
- Ķ»äõ╝░µÅÉńż║µĆ¦ĶāĮ’╝Üńö¤µłÉńÜäµÅÉńż║õ╝ÜĶó½ńö©µØźµē¦ĶĪīÕģĘõĮōõ╗╗ÕŖĪ’╝īÕ╣ČķĆÜĶ┐ćĶ»äõ╝░µ©ĪÕØŚµĄŗķćÅÕģȵƦĶāĮŃĆéĶ┐ÖõĖ¬µĆ¦ĶāĮĶĪ©ńÄ░õĮ£õĖ║Õź¢ÕŖ▒õ┐ĪÕÅĘÕÅŹķ”łń╗ÖRLń«Śµ│Ģ’╝īÕĖ«ÕŖ®õ╝śÕī¢µÅÉńż║ŃĆé
- RLµø┤µ¢░’╝ÜRLµ©ĪÕ×ŗµĀ╣µŹ«ĶÄĘÕŠŚńÜäÕź¢ÕŖ▒õ┐ĪÕÅĘ’╝łÕ¤║õ║ĵÅÉńż║ĶĪ©ńÄ░’╝ēµØźµø┤µ¢░Ķć¬Ķ║½’╝īķĆɵĖÉõ╝śÕī¢µÅÉńż║ÕåģÕ«╣’╝īõ╗ÄĶĆīµÅÉÕŹćµ©ĪÕ×ŗÕ£©ńē╣Õ«Üõ╗╗ÕŖĪõĖŖńÜäĶĪ©ńÄ░ŃĆéĶ┐ÖõĖ¬Ķ┐ćń©ŗÕ£©ÕżÜõĖ¬µŚČķŚ┤µŁźÕåģÕÅŹÕżŹĶ┐Łõ╗Ż’╝īµ£Ćń╗łńö¤µłÉķ½śµĢłńÜäµÅÉńż║ŃĆé
2. RLPromptµ©ĪÕØŚ
- ÕÅ│õĖŖĶ¦Æķā©ÕłåÕ▒Ģńż║ńÜ䵜»RLPromptµ©ĪÕØŚ’╝īĶ┐ÖõĖƵ©ĪÕØŚõĮ┐ńö©õ╗╗ÕŖĪńē╣Õ«ÜńÜäMLP’╝łÕżÜÕ▒éµä¤ń¤źÕÖ©’╝ēµØźńö¤µłÉÕ╣ČĶ»äõ╝░µÅÉńż║ŃĆéRLPromptÕÉīµŚČµö»µīüµÄ®ńĀüĶ»ŁĶ©Ćµ©ĪÕ×ŗ’╝łMasked LM’╝ēÕÆīĶć¬Õø×ÕĮÆĶ»ŁĶ©Ćµ©ĪÕ×ŗ’╝łLeft-to-Right LM’╝ē’╝īÕ╣ȵĀ╣µŹ«õĖŹÕÉīµÅÉńż║Õ£©õ╗╗ÕŖĪõĖŁńö¤µłÉńÜäÕź¢ÕŖ▒Ķ┐øĶĪīõ╝śÕī¢ŃĆé
- ÕĘźõĮ£µ£║ÕłČ’╝ÜRLPromptµ©ĪÕØŚńö¤µłÉµÅÉńż║ÕÉÄ’╝īMasked LMµł¢Left-to-Right LMõ╝ÜÕ║öńö©Ķ┐Öõ║øµÅÉńż║Õ£©ÕģĘõĮōõ╗╗ÕŖĪõĖŁĶ┐øĶĪīµÄ©ńÉå’╝īõ║¦ńö¤ńøĖÕ║öńÜäÕź¢ÕŖ▒ŃĆéõŠŗÕ”é’╝īLeft-to-Right LMÕ¤║õ║ĵÅÉńż║ńö¤µłÉÕÅźÕŁÉÕ╣ČĶĄŗõ║łÕź¢ÕŖ▒’╝łÕ”éÕøŠõĖŁŌĆ£Food is deliciousŌĆØĶó½ĶĄŗõ║łõ║å86.3ńÜäÕź¢ÕŖ▒ÕłåµĢ░’╝ē’╝īĶ┐Öń▒╗ÕÅŹķ”łķĆÜĶ┐ćRLõ╝śÕī¢µÅÉńż║ńö¤µłÉńŁ¢ńĢźŃĆé
3. TEMPERAµ©ĪÕØŚ
- ÕÅ│õĖŗµ¢╣ķā©ÕłåÕ▒Ģńż║õ║åTEMPERAµ©ĪÕØŚ’╝īĶ┐ÖõĖƵ©ĪÕØŚÕīģÕɽõĖĆõĖ¬ŌĆ£ń╝¢ĶŠæõ╗ŻńÉåŌĆØ’╝łEdit Agent’╝ē’╝īńö©õ║ÄÕ¤║õ║ÄÕĤզŗµÅÉńż║ķĆɵŁźõ╝śÕī¢µÅÉńż║ÕåģÕ«╣ŃĆéÕģČĶ┐ćń©ŗÕłåõĖ║õĖēµŁź’╝Ü
1. ĶŠōÕģźÕĤզŗµÅÉńż║’╝ÜÕ░åÕłØÕ¦ŗµÅÉńż║’╝łÕīģµŗ¼õ╗╗ÕŖĪµīćõ╗żÕÆīÕģĘõĮōõŠŗÕŁÉ’╝ēĶŠōÕģźń│╗ń╗¤ŃĆé
2. Attentionµ£║ÕłČõ╝śÕī¢’╝ÜAttentionÕ▒éµĀ╣µŹ«õĖŖõĖŗµ¢ćķĆēµŗ®Õ╣Čńö¤µłÉń╝¢ĶŠæÕåģÕ«╣’╝īĶ┐øõĖƵŁźÕó×Õ╝║µÅÉńż║ńÜäÕćåńĪ«µĆ¦ŃĆé
3. ńö¤µłÉµ£Ćń╗łµÅÉńż║’╝ÜÕ£©ń╗ÅĶ┐ćń╝¢ĶŠæÕÆīõ╝śÕī¢ÕÉÄ’╝īńö¤µłÉµ£Ćń╗łµÅÉńż║õ╗źÕ«×ńÄ░µø┤õ╝śõ╗╗ÕŖĪĶĪ©ńÄ░ŃĆé
µĆ╗ń╗ō
Ķ»źÕøŠĶĪ©µśÄ’╝īµĢ┤õĖ¬õ╝śÕī¢µĄüń©ŗķĆÜĶ┐ćÕ╝║Õī¢ÕŁ”õ╣ĀÕÆīÕżÜµ¼ĪÕÅŹķ”łĶ┐Łõ╗Ż’╝īķĆɵŁźĶ░āµĢ┤ńö¤µłÉÕ╝ÅĶ»ŁĶ©Ćµ©ĪÕ×ŗńÜäµÅÉńż║ÕåģÕ«╣’╝īõĮ┐õ╣ŗÕ£©ńē╣Õ«Üõ╗╗ÕŖĪ’╝łÕ”éµ¢ćµ£¼Õłåń▒╗ŃĆüÕåģÕ«╣ńö¤µłÉńŁē’╝ēõĖŖĶĪ©ńÄ░µø┤ÕźĮŃĆé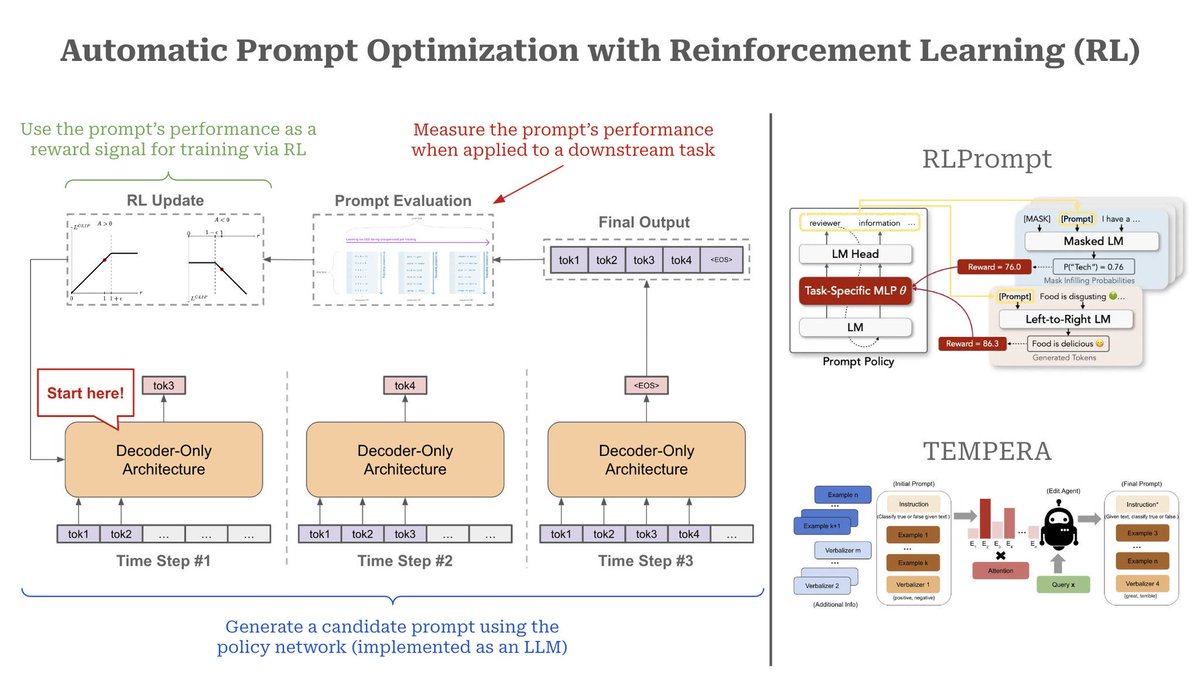
1. µĄüń©ŗµ”éĶ┐░
- ńö¤µłÉÕĆÖķĆēµÅÉńż║’╝ÜÕĘ”õŠ¦ÕøŠńż║õĖŁ’╝īDecoder-Onlyµ×ȵ×ä’╝łÕ”éGPTń▒╗µ©ĪÕ×ŗ’╝ēÕ£©µ»ÅõĖ¬µŚČķŚ┤µŁź’╝łTime Step’╝ēńö¤µłÉõĖĆõĖ¬ÕĆÖķĆēµÅÉńż║’╝īķĆɵŁźµ×äÕ╗║ÕÅ»ĶāĮµ£ēµĢłńÜäµÅÉńż║ÕåģÕ«╣ŃĆé
- Ķ»äõ╝░µÅÉńż║µĆ¦ĶāĮ’╝Üńö¤µłÉńÜäµÅÉńż║õ╝ÜĶó½ńö©µØźµē¦ĶĪīÕģĘõĮōõ╗╗ÕŖĪ’╝īÕ╣ČķĆÜĶ┐ćĶ»äõ╝░µ©ĪÕØŚµĄŗķćÅÕģȵƦĶāĮŃĆéĶ┐ÖõĖ¬µĆ¦ĶāĮĶĪ©ńÄ░õĮ£õĖ║Õź¢ÕŖ▒õ┐ĪÕÅĘÕÅŹķ”łń╗ÖRLń«Śµ│Ģ’╝īÕĖ«ÕŖ®õ╝śÕī¢µÅÉńż║ŃĆé
- RLµø┤µ¢░’╝ÜRLµ©ĪÕ×ŗµĀ╣µŹ«ĶÄĘÕŠŚńÜäÕź¢ÕŖ▒õ┐ĪÕÅĘ’╝łÕ¤║õ║ĵÅÉńż║ĶĪ©ńÄ░’╝ēµØźµø┤µ¢░Ķć¬Ķ║½’╝īķĆɵĖÉõ╝śÕī¢µÅÉńż║ÕåģÕ«╣’╝īõ╗ÄĶĆīµÅÉÕŹćµ©ĪÕ×ŗÕ£©ńē╣Õ«Üõ╗╗ÕŖĪõĖŖńÜäĶĪ©ńÄ░ŃĆéĶ┐ÖõĖ¬Ķ┐ćń©ŗÕ£©ÕżÜõĖ¬µŚČķŚ┤µŁźÕåģÕÅŹÕżŹĶ┐Łõ╗Ż’╝īµ£Ćń╗łńö¤µłÉķ½śµĢłńÜäµÅÉńż║ŃĆé
2. RLPromptµ©ĪÕØŚ
- ÕÅ│õĖŖĶ¦Æķā©ÕłåÕ▒Ģńż║ńÜ䵜»RLPromptµ©ĪÕØŚ’╝īĶ┐ÖõĖƵ©ĪÕØŚõĮ┐ńö©õ╗╗ÕŖĪńē╣Õ«ÜńÜäMLP’╝łÕżÜÕ▒éµä¤ń¤źÕÖ©’╝ēµØźńö¤µłÉÕ╣ČĶ»äõ╝░µÅÉńż║ŃĆéRLPromptÕÉīµŚČµö»µīüµÄ®ńĀüĶ»ŁĶ©Ćµ©ĪÕ×ŗ’╝łMasked LM’╝ēÕÆīĶć¬Õø×ÕĮÆĶ»ŁĶ©Ćµ©ĪÕ×ŗ’╝łLeft-to-Right LM’╝ē’╝īÕ╣ȵĀ╣µŹ«õĖŹÕÉīµÅÉńż║Õ£©õ╗╗ÕŖĪõĖŁńö¤µłÉńÜäÕź¢ÕŖ▒Ķ┐øĶĪīõ╝śÕī¢ŃĆé
- ÕĘźõĮ£µ£║ÕłČ’╝ÜRLPromptµ©ĪÕØŚńö¤µłÉµÅÉńż║ÕÉÄ’╝īMasked LMµł¢Left-to-Right LMõ╝ÜÕ║öńö©Ķ┐Öõ║øµÅÉńż║Õ£©ÕģĘõĮōõ╗╗ÕŖĪõĖŁĶ┐øĶĪīµÄ©ńÉå’╝īõ║¦ńö¤ńøĖÕ║öńÜäÕź¢ÕŖ▒ŃĆéõŠŗÕ”é’╝īLeft-to-Right LMÕ¤║õ║ĵÅÉńż║ńö¤µłÉÕÅźÕŁÉÕ╣ČĶĄŗõ║łÕź¢ÕŖ▒’╝łÕ”éÕøŠõĖŁŌĆ£Food is deliciousŌĆØĶó½ĶĄŗõ║łõ║å86.3ńÜäÕź¢ÕŖ▒ÕłåµĢ░’╝ē’╝īĶ┐Öń▒╗ÕÅŹķ”łķĆÜĶ┐ćRLõ╝śÕī¢µÅÉńż║ńö¤µłÉńŁ¢ńĢźŃĆé
3. TEMPERAµ©ĪÕØŚ
- ÕÅ│õĖŗµ¢╣ķā©ÕłåÕ▒Ģńż║õ║åTEMPERAµ©ĪÕØŚ’╝īĶ┐ÖõĖƵ©ĪÕØŚÕīģÕɽõĖĆõĖ¬ŌĆ£ń╝¢ĶŠæõ╗ŻńÉåŌĆØ’╝łEdit Agent’╝ē’╝īńö©õ║ÄÕ¤║õ║ÄÕĤզŗµÅÉńż║ķĆɵŁźõ╝śÕī¢µÅÉńż║ÕåģÕ«╣ŃĆéÕģČĶ┐ćń©ŗÕłåõĖ║õĖēµŁź’╝Ü
1. ĶŠōÕģźÕĤզŗµÅÉńż║’╝ÜÕ░åÕłØÕ¦ŗµÅÉńż║’╝łÕīģµŗ¼õ╗╗ÕŖĪµīćõ╗żÕÆīÕģĘõĮōõŠŗÕŁÉ’╝ēĶŠōÕģźń│╗ń╗¤ŃĆé
2. Attentionµ£║ÕłČõ╝śÕī¢’╝ÜAttentionÕ▒éµĀ╣µŹ«õĖŖõĖŗµ¢ćķĆēµŗ®Õ╣Čńö¤µłÉń╝¢ĶŠæÕåģÕ«╣’╝īĶ┐øõĖƵŁźÕó×Õ╝║µÅÉńż║ńÜäÕćåńĪ«µĆ¦ŃĆé
3. ńö¤µłÉµ£Ćń╗łµÅÉńż║’╝ÜÕ£©ń╗ÅĶ┐ćń╝¢ĶŠæÕÆīõ╝śÕī¢ÕÉÄ’╝īńö¤µłÉµ£Ćń╗łµÅÉńż║õ╗źÕ«×ńÄ░µø┤õ╝śõ╗╗ÕŖĪĶĪ©ńÄ░ŃĆé
µĆ╗ń╗ō
Ķ»źÕøŠĶĪ©µśÄ’╝īµĢ┤õĖ¬õ╝śÕī¢µĄüń©ŗķĆÜĶ┐ćÕ╝║Õī¢ÕŁ”õ╣ĀÕÆīÕżÜµ¼ĪÕÅŹķ”łĶ┐Łõ╗Ż’╝īķĆɵŁźĶ░āµĢ┤ńö¤µłÉÕ╝ÅĶ»ŁĶ©Ćµ©ĪÕ×ŗńÜäµÅÉńż║ÕåģÕ«╣’╝īõĮ┐õ╣ŗÕ£©ńē╣Õ«Üõ╗╗ÕŖĪ’╝łÕ”éµ¢ćµ£¼Õłåń▒╗ŃĆüÕåģÕ«╣ńö¤µłÉńŁē’╝ēõĖŖĶĪ©ńÄ░µø┤ÕźĮŃĆé