
GPTDAOCN-e/acc on Nostr: йңҮж’јжқҘиўӯпјҒLlama MultimodalеҚіе°Ҷзҷ»еңәпјҢејҖжәҗзӨҫеҢәиҝҺжқҘж–°зәӘе…ғпјҒ ...
йңҮж’јжқҘиўӯпјҒLlama MultimodalеҚіе°Ҷзҷ»еңәпјҢејҖжәҗзӨҫеҢәиҝҺжқҘж–°зәӘе…ғпјҒ
MetaеҶҚж¬Ўеұ•зҺ°е…¶еҜ№ејҖжәҗзҡ„еқҡе®ҡжүҝиҜәпјҢжҺЁеҮәдәҶеӨҡжЁЎжҖҒжЁЎеһӢLlama MultimodalпјҢиҝҷж— з–‘жҳҜејҖжәҗзӨҫеҢәзҡ„дёҖеӨ§зҰҸйҹігҖӮдёӢйқўиҜҰз»Ҷи§ЈиҜ»дёҖдёӢеӣҫдёӯзҡ„еҶ…е®№пјҡ
жЁЎеһӢеҜ№жҜ”
еӣҫиЎЁеұ•зӨәдәҶдёҚеҗҢжЁЎеһӢеңЁеӨҡдёӘеҹәеҮҶжөӢиҜ•дёӯзҡ„иЎЁзҺ°пјҢеҢ…жӢ¬Llama 3.2 11BгҖҒLlama 3.2 90BгҖҒClaude3-Haikuе’ҢGPT-4o-miniгҖӮиҝҷдәӣеҹәеҮҶжөӢиҜ•иҰҶзӣ–дәҶж•°еӯҰжҺЁзҗҶгҖҒеӣҫиЎЁзҗҶи§ЈгҖҒи§Ҷи§үй—®зӯ”зӯүеӨҡз§Қд»»еҠЎгҖӮ
еҗ„йЎ№жөӢиҜ•жҲҗз»©
1. College-level Problems and Mathematical Reasoning
- MMMU (Micro avg accuracy): Llama 3.2 90Bеҫ—еҲҶжңҖй«ҳпјҢиҫҫеҲ°60.3гҖӮ
- MMMU-Pro, Standard: Llama 3.2 90Bдҫқ然йўҶе…ҲпјҢеҫ—еҲҶ45.2гҖӮ
- MMMU-Pro, Vision: GPT-4o-miniд»Ҙ36.5зҡ„еҫ—еҲҶз•ҘиғңдёҖзӯ№гҖӮ
- MathVista: Llama 3.2 90Bеҫ—еҲҶ57.3пјҢиЎЁзҺ°жңҖдҪігҖӮ
2. Charts and Diagram Understanding
- ChartQA: Llama 3.2 90Bд»Ҙ85.5зҡ„й«ҳеҲҶйўҶе…ҲгҖӮ
- AI2 Diagram: Llama 3.2 90BеҶҚеәҰжӢ”еҫ—еӨҙзӯ№пјҢеҫ—еҲҶ92.3гҖӮ
- DocVQA: Llama 3.2 90Bеҫ—еҲҶ90.1пјҢиЎЁзҺ°зӘҒеҮәгҖӮ
3. General Visual Question Answering
- VQAv2 (Image): Llama 3.2 90Bеҫ—еҲҶ78.1пјҢеҶҚж¬ЎйўҶе…ҲгҖӮ
4. Text-Based Tasks
- General VQAv2: Llama 3.2 90BиЎЁзҺ°жңҖдјҳпјҢеҫ—еҲҶ86гҖӮ
- Math VQAv2: GPT-4o-miniд»Ҙ70.2зҡ„й«ҳеҲҶдҪҚеұ…第дёҖгҖӮ
- Reasoning VQAv2: Llama 3.2 90Bеҫ—еҲҶ46.7пјҢеҶҚж¬ЎйўҶе…ҲгҖӮ
- Multilingual VQAv2: GPT-4o-miniд»Ҙ87зҡ„й«ҳеҲҶеӨәеҶ гҖӮ
жҖ»з»“
д»Һж•ҙдҪ“иЎЁзҺ°жқҘзңӢпјҢLlamaзі»еҲ—е°Өе…¶жҳҜLlama 3.2 90BеңЁеӨҡдёӘеҹәеҮҶжөӢиҜ•дёӯиЎЁзҺ°еҮәиүІпјҢжҳҫзӨәдәҶе…¶ејәеӨ§зҡ„еӨҡжЁЎжҖҒеӨ„зҗҶиғҪеҠӣгҖӮMetaзҡ„иҝҷдёҖеҲӣж–°дёҚд»…еЎ«иЎҘдәҶејҖжәҗзӨҫеҢәеңЁеӨҡжЁЎжҖҒжЁЎеһӢж–№йқўзҡ„з©әзҷҪпјҢд№ҹдёәжңӘжқҘзҡ„з ”з©¶е’Ңеә”з”ЁжҸҗдҫӣдәҶеқҡе®һзҡ„еҹәзЎҖгҖӮи®©жҲ‘们дёҖиө·жңҹеҫ…Llama MultimodalдёәжҲ‘们еёҰжқҘжӣҙеӨҡжғҠе–ңеҗ§пјҒ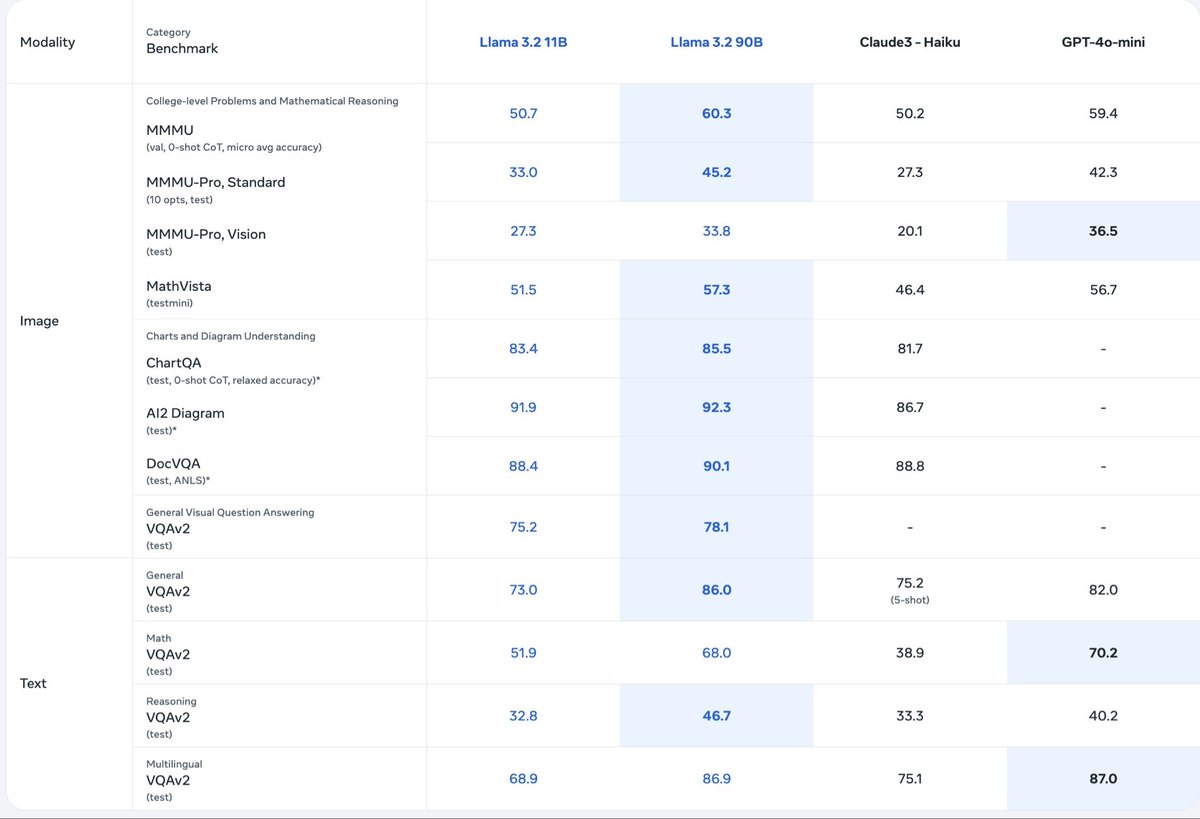
MetaеҶҚж¬Ўеұ•зҺ°е…¶еҜ№ејҖжәҗзҡ„еқҡе®ҡжүҝиҜәпјҢжҺЁеҮәдәҶеӨҡжЁЎжҖҒжЁЎеһӢLlama MultimodalпјҢиҝҷж— з–‘жҳҜејҖжәҗзӨҫеҢәзҡ„дёҖеӨ§зҰҸйҹігҖӮдёӢйқўиҜҰз»Ҷи§ЈиҜ»дёҖдёӢеӣҫдёӯзҡ„еҶ…е®№пјҡ
жЁЎеһӢеҜ№жҜ”
еӣҫиЎЁеұ•зӨәдәҶдёҚеҗҢжЁЎеһӢеңЁеӨҡдёӘеҹәеҮҶжөӢиҜ•дёӯзҡ„иЎЁзҺ°пјҢеҢ…жӢ¬Llama 3.2 11BгҖҒLlama 3.2 90BгҖҒClaude3-Haikuе’ҢGPT-4o-miniгҖӮиҝҷдәӣеҹәеҮҶжөӢиҜ•иҰҶзӣ–дәҶж•°еӯҰжҺЁзҗҶгҖҒеӣҫиЎЁзҗҶи§ЈгҖҒи§Ҷи§үй—®зӯ”зӯүеӨҡз§Қд»»еҠЎгҖӮ
еҗ„йЎ№жөӢиҜ•жҲҗз»©
1. College-level Problems and Mathematical Reasoning
- MMMU (Micro avg accuracy): Llama 3.2 90Bеҫ—еҲҶжңҖй«ҳпјҢиҫҫеҲ°60.3гҖӮ
- MMMU-Pro, Standard: Llama 3.2 90Bдҫқ然йўҶе…ҲпјҢеҫ—еҲҶ45.2гҖӮ
- MMMU-Pro, Vision: GPT-4o-miniд»Ҙ36.5зҡ„еҫ—еҲҶз•ҘиғңдёҖзӯ№гҖӮ
- MathVista: Llama 3.2 90Bеҫ—еҲҶ57.3пјҢиЎЁзҺ°жңҖдҪігҖӮ
2. Charts and Diagram Understanding
- ChartQA: Llama 3.2 90Bд»Ҙ85.5зҡ„й«ҳеҲҶйўҶе…ҲгҖӮ
- AI2 Diagram: Llama 3.2 90BеҶҚеәҰжӢ”еҫ—еӨҙзӯ№пјҢеҫ—еҲҶ92.3гҖӮ
- DocVQA: Llama 3.2 90Bеҫ—еҲҶ90.1пјҢиЎЁзҺ°зӘҒеҮәгҖӮ
3. General Visual Question Answering
- VQAv2 (Image): Llama 3.2 90Bеҫ—еҲҶ78.1пјҢеҶҚж¬ЎйўҶе…ҲгҖӮ
4. Text-Based Tasks
- General VQAv2: Llama 3.2 90BиЎЁзҺ°жңҖдјҳпјҢеҫ—еҲҶ86гҖӮ
- Math VQAv2: GPT-4o-miniд»Ҙ70.2зҡ„й«ҳеҲҶдҪҚеұ…第дёҖгҖӮ
- Reasoning VQAv2: Llama 3.2 90Bеҫ—еҲҶ46.7пјҢеҶҚж¬ЎйўҶе…ҲгҖӮ
- Multilingual VQAv2: GPT-4o-miniд»Ҙ87зҡ„й«ҳеҲҶеӨәеҶ гҖӮ
жҖ»з»“
д»Һж•ҙдҪ“иЎЁзҺ°жқҘзңӢпјҢLlamaзі»еҲ—е°Өе…¶жҳҜLlama 3.2 90BеңЁеӨҡдёӘеҹәеҮҶжөӢиҜ•дёӯиЎЁзҺ°еҮәиүІпјҢжҳҫзӨәдәҶе…¶ејәеӨ§зҡ„еӨҡжЁЎжҖҒеӨ„зҗҶиғҪеҠӣгҖӮMetaзҡ„иҝҷдёҖеҲӣж–°дёҚд»…еЎ«иЎҘдәҶејҖжәҗзӨҫеҢәеңЁеӨҡжЁЎжҖҒжЁЎеһӢж–№йқўзҡ„з©әзҷҪпјҢд№ҹдёәжңӘжқҘзҡ„з ”з©¶е’Ңеә”з”ЁжҸҗдҫӣдәҶеқҡе®һзҡ„еҹәзЎҖгҖӮи®©жҲ‘们дёҖиө·жңҹеҫ…Llama MultimodalдёәжҲ‘们еёҰжқҘжӣҙеӨҡжғҠе–ңеҗ§пјҒ