
向阳乔木 on Nostr: Lex ...
Lex Fridman的播客经常会采访一些大牛,搜到个Kaggle上的数据集,有300多期访谈CSV文件。
https://t.co/sHNLx6neMx
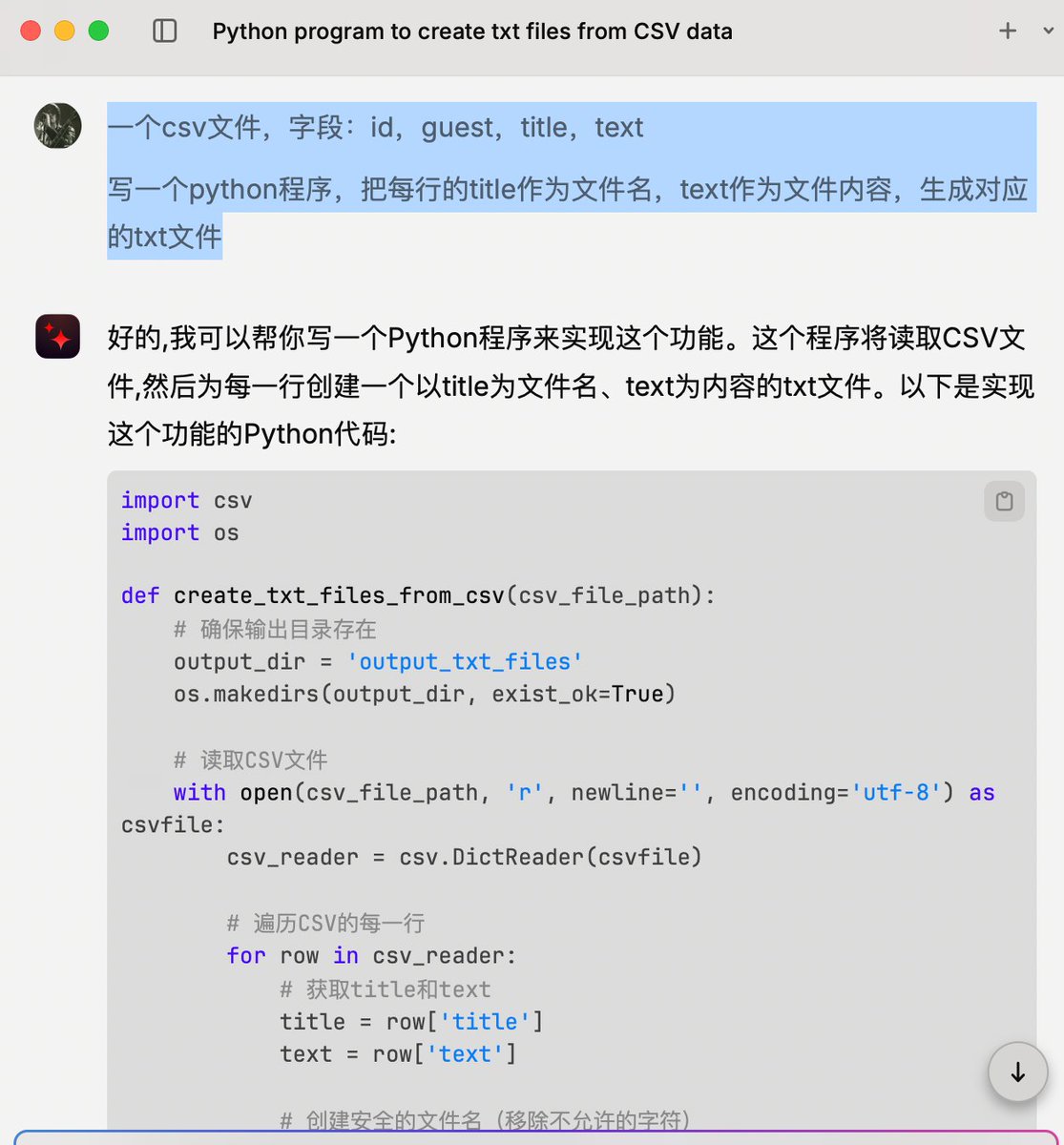
下载后让Claude写个Python程序生成300个txt文件,传到notebookLM使用。
生成文件Python代码:
import csv
import os
import sys
# 增加CSV字段大小限制
csv.field_size_limit(sys.maxsize)
def create_txt_files_from_csv(csv_file_path):
# 确保输出目录存在
output_dir = 'output_txt_files'
os.makedirs(output_dir, exist_ok=True)
# 读取CSV文件
with open(csv_file_path, 'r', newline='', encoding='utf-8') as csvfile:
csv_reader = csv.DictReader(csvfile)
# 遍历CSV的每一行
for row in csv_reader:
# 获取title和text
title = row['title']
text = row['text']
# 创建安全的文件名(移除不允许的字符)
safe_title = "".join([c for c in title if c.isalpha() or c.isdigit() or c==' ']).rstrip()
# 如果文件名为空,使用id作为文件名
if not safe_title:
safe_title = f"file_{row['id']}"
# 创建文件路径
file_path = os.path.join(output_dir, f"{safe_title}.txt")
# 写入文本文件
with open(file_path, 'w', encoding='utf-8') as txtfile:
txtfile.write(text)
print(f"Created file: {file_path}")
# 使用函数
csv_file_path = 'podcastdata_dataset.csv' # 替换为你的CSV文件路径
create_txt_files_from_csv(csv_file_path)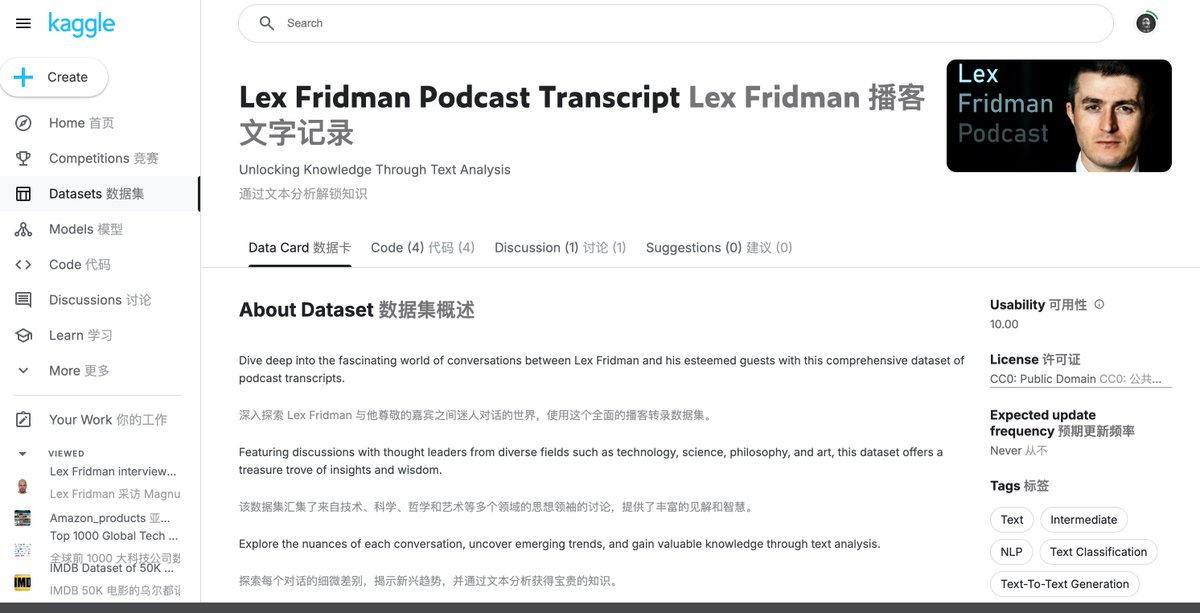

https://t.co/sHNLx6neMx
下载后让Claude写个Python程序生成300个txt文件,传到notebookLM使用。
生成文件Python代码:
import csv
import os
import sys
# 增加CSV字段大小限制
csv.field_size_limit(sys.maxsize)
def create_txt_files_from_csv(csv_file_path):
# 确保输出目录存在
output_dir = 'output_txt_files'
os.makedirs(output_dir, exist_ok=True)
# 读取CSV文件
with open(csv_file_path, 'r', newline='', encoding='utf-8') as csvfile:
csv_reader = csv.DictReader(csvfile)
# 遍历CSV的每一行
for row in csv_reader:
# 获取title和text
title = row['title']
text = row['text']
# 创建安全的文件名(移除不允许的字符)
safe_title = "".join([c for c in title if c.isalpha() or c.isdigit() or c==' ']).rstrip()
# 如果文件名为空,使用id作为文件名
if not safe_title:
safe_title = f"file_{row['id']}"
# 创建文件路径
file_path = os.path.join(output_dir, f"{safe_title}.txt")
# 写入文本文件
with open(file_path, 'w', encoding='utf-8') as txtfile:
txtfile.write(text)
print(f"Created file: {file_path}")
# 使用函数
csv_file_path = 'podcastdata_dataset.csv' # 替换为你的CSV文件路径
create_txt_files_from_csv(csv_file_path)