melvincarvalho on Nostr: Tencent Hunyuan Large - 389B (Total) X 52B (Active) - beats Llama 3.1 405B, Mistral ...
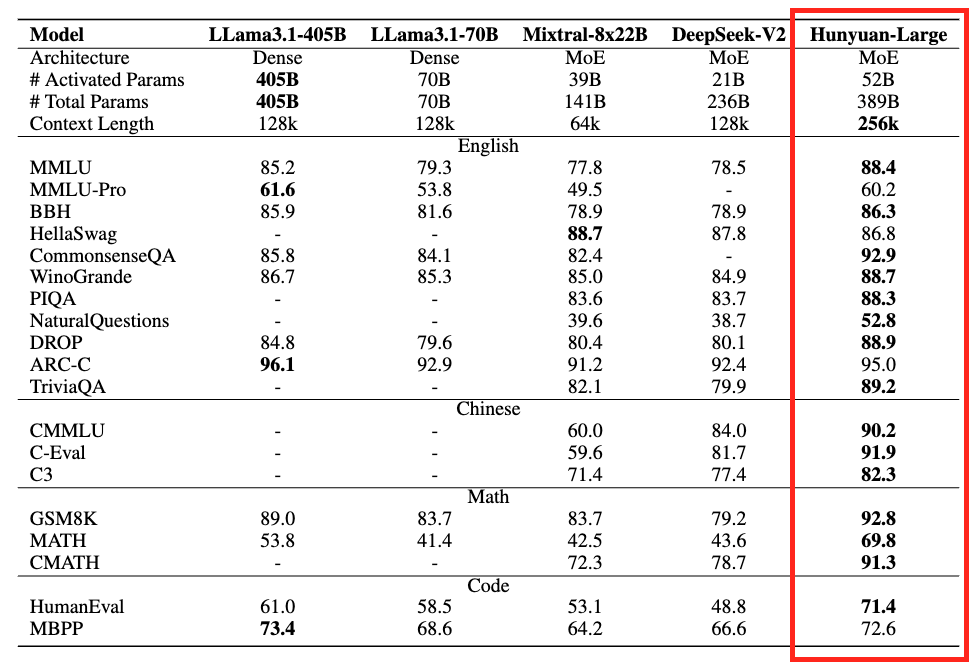
Tencent Hunyuan Large - 389B (Total) X 52B (Active) - beats Llama 3.1 405B, Mistral 8x22B, DeepSeek V2!
Multilingual, 128K context, Utilizes GQA + CLA for KV Cache compression + Higher throughput
Released Pre-train, Instruct & FP8 checkpoints on the Hugging Face Hub!
Published at
2024-12-03 15:25:19Event JSON
{
"id": "3631b992bfdd5c50a49e0fbb3b679ad16d6a68d6b49d0463327842307f9b951d",
"pubkey": "de7ecd1e2976a6adb2ffa5f4db81a7d812c8bb6698aa00dcf1e76adb55efd645",
"created_at": 1733239519,
"kind": 1,
"tags": [
[
"imeta",
"url https://image.nostr.build/bcdae6637477739a274d2234748fd639387138c72edc8285ffbaf9746fc7b367.png",
"m image/png",
"x a0721c7ad8d14b24612b2f6b3819aceb141d6201540a3f5b0894d077af5ae3a4",
"ox bcdae6637477739a274d2234748fd639387138c72edc8285ffbaf9746fc7b367",
"size 45982",
"dim 979x671",
"blurhash LBR:7[.mHryD%MWBf6j[DibvxGtR"
]
],
"content": "Tencent Hunyuan Large - 389B (Total) X 52B (Active) - beats Llama 3.1 405B, Mistral 8x22B, DeepSeek V2!\n\nMultilingual, 128K context, Utilizes GQA + CLA for KV Cache compression + Higher throughput\n\nReleased Pre-train, Instruct \u0026 FP8 checkpoints on the Hugging Face Hub!\n\nhttps://image.nostr.build/bcdae6637477739a274d2234748fd639387138c72edc8285ffbaf9746fc7b367.png",
"sig": "adb4533ef736103779ff72958ffb821953163d2fe0e60eae30cc393e12594559c2f1b234ad7640029dfe8400466159eda68645ddcf00710dbdafaa7a0ebd9762"
}
