
GPTDAOCN-e/acc on Nostr: čÜÇ Llama-3.2ň╝ĽÚó抾çŠíúŔüŐňĄęŠľ░š║¬ňůâ´╝ÜRAGŠÁüšĘőňůĘÚŁóŔžúŠ×É´╝ü čôÜ襾 ...
čÜÇ Llama-3.2ň╝ĽÚó抾çŠíúŔüŐňĄęŠľ░š║¬ňůâ´╝ÜRAGŠÁüšĘőňůĘÚŁóŔžúŠ×É´╝ü čôÜ襾
Ŕ┐Öň╝áňŤżŔžúň▒ĽšĄ║ń║ćňŽéńŻĽńŻ┐šöĘLlama-3.2ň«×šÄ░ŠľçŠíúŔüŐňĄęšÜäŠúÇš┤óňó×ň╝║šö芳ɴ╝łRAG´╝ëŠÁüšĘőŃÇéňůĚńŻôŠşąÚ¬ĄňŽéńŞő´╝Ü
1. ščąŔ»ćň║ô (Knowledge Base)
- ÚŽľňůł´╝Ĺń╗ČŠťëńŞÇńެščąŔ»ćň║ô´╝îňůÂńŞşňîůňÉźňÉäšžŹŠľçŠíúŃÇé
2. ňłćňŁŚ (Chunking)
- Ŕ┐Öń║ŤŠľçŠíúŔóźňłćŠłÉŔőąň╣▓ň░ĆňŁŚ´╝ĆńެňŁŚń╗úŔíĘŠľçŠíúšÜäńŞÇÚâĘňłćňćůň«╣ŃÇé
3. ňÁîňůąŠĘíň×ő (Embedding Model)
- Š»ĆńެňŁŚÚÇÜŔ┐çňÁîňůąŠĘíň×őŔŻČňîľńŞ║ňÉĹÚçĆ´╝îŔ┐Öń║ŤňÉĹÚçĆŠś»ŔíĘšĄ║ŠľçŠťČňćůň«╣šÜäÚźśš╗┤ŠĽ░ŠŹ«šé╣ŃÇé
4. ňÉĹÚçĆŠĽ░ŠŹ«ň║ô (Vector Database)
- ŠëÇŠťëŔ┐Öń║ŤňÁîňůąňÉĹÚçĆŔóźňşśňéĘňťĘńŞÇńެňÉĹÚçĆŠĽ░ŠŹ«ň║ôńŞşŃÇéŔ»ąŠĽ░ŠŹ«ň║ôňîůŠőČš┤óň╝ĽŃÇüňÁîňůąŃÇüŠľçŠťČňŁŚňĺîňů⊼░ŠŹ«ŃÇé
- ňťĘŠĽ░ŠŹ«ň║ôńŞş´╝îŠčąŔ»óňÉĹÚçĆńŞÄšŤŞń╝╝ňÉĹÚçĆń╣őÚŚ┤šÜäňů│š│╗ňĆ»ń╗ąňŞ«ňŐęŠúÇš┤óŠťÇšŤŞňů│šÜäń┐íŠü»ŃÇé
5. ŠĆÉšĄ║ŠĘ튣┐ (Prompt Template)
- ŠĆÉšĄ║ŠĘ튣┐Šá╣ŠŹ«ŠčąŔ»óŠĆÉńżŤńŞŐńŞőŠľç´╝îŠî皥║ÚťÇŔŽüňŤ×šşöšÜäÚŚ«Úóśń╗ąňĆŐšŤŞňů│šÜäńŞŐńŞőŠľçń┐íŠü»ŃÇé
6. Llama-3.2ŠĘíň×ő (Llama-3.2 LLM)
- Llama-3.2ňĄžŔ»şŔĘÇŠĘíň×őŠá╣ŠŹ«ŠĆÉšĄ║ŠĘ튣┐šö芳ÉňôŹň║öŃÇéŔ┐ÖńŞÇŔ┐çšĘőňîůŠőČń╗ÄŠĆÉšĄ║ńŞşŔÄĚňĆľńŞŐńŞőŠľç´╝îň╣Âňč║ń║ÄŠşĄšö芳ɚŤŞň║öšşöŠíłŃÇé
7. šöĘŠłĚšĽîÚŁó (User Interface)
- ŠťÇš╗łšÜäňôŹň║öÚÇÜŔ┐çšöĘŠłĚšĽîÚŁóŔ┐öňŤ×š╗ÖšöĘŠłĚŃÇéńżőňŽé´╝îšöĘŠłĚňĆ»ń╗ąÚÇÜŔ┐çŠÄąňĆúÔÇťChatWithYourCode!ÔÇŁŔ┐ŤŔíîŠĆÉÚŚ«ň╣ŠĹŠöŠťÇš╗łšşöŠíłŃÇé
ŠÇ╗š╗ô
ŠŹ«https://t.co/St5O59mmxtňłćŠ×É´╝îŔ»ąŠÁüšĘőŔ»Žš╗ćŔ»┤ŠśÄń║ćňŽéńŻĽň░抾çŠíúňłćňŁŚň╣ÂňşśňéĘńŞ║ňÁîňůąňÉĹÚçĆ´╝îÚÇÜŔ┐çňÉĹÚçĆŠĽ░ŠŹ«ň║ôŔ┐ŤŔíîÚźśŠĽłŠúÇš┤ó´╝îšäÂňÉÄňłęšöĘLlama-3.2ŠĘíň×őšö芳ÉŔ笚äÂŔ»şŔĘÇňôŹň║öŃÇéŔ┐ÖšžŹŠľ╣Š│ĽńŞŹń╗ůŠĆÉÚźśń║ćń┐íŠü»ŠúÇš┤óšÜäňçćší«ŠÇž´╝îŔ┐śŔ⯊ĆÉńżŤŠŤ┤ŠÖ║ŔâŻňĺîńŞŐńŞőŠľçšŤŞňů│šÜäšşöŠíł´╝îńŻ┐ňżŚšöĘŠłĚńŻôڬ┤ňŐáŠÁüšĽůňĺîÚźśŠĽłŃÇé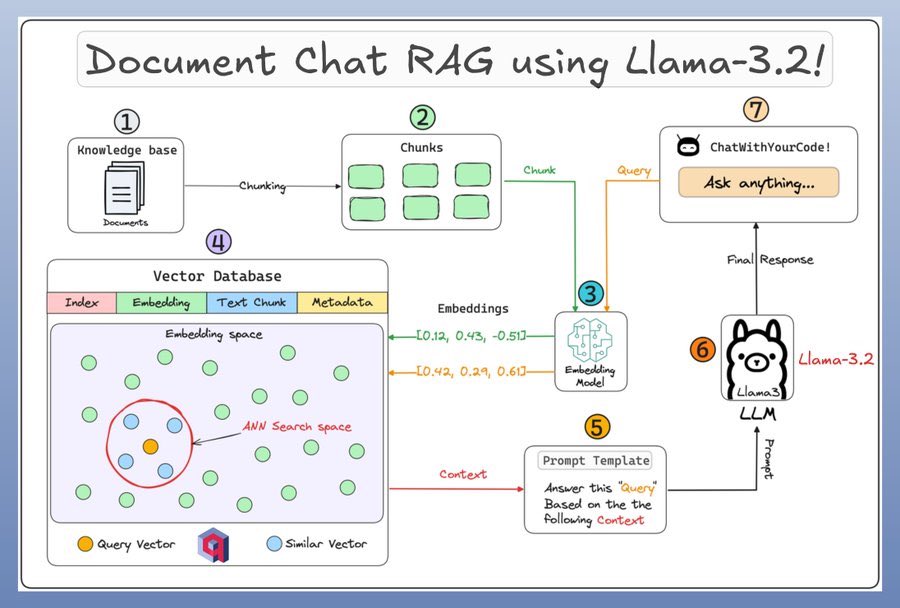
Ŕ┐Öň╝áňŤżŔžúň▒ĽšĄ║ń║ćňŽéńŻĽńŻ┐šöĘLlama-3.2ň«×šÄ░ŠľçŠíúŔüŐňĄęšÜäŠúÇš┤óňó×ň╝║šö芳ɴ╝łRAG´╝ëŠÁüšĘőŃÇéňůĚńŻôŠşąÚ¬ĄňŽéńŞő´╝Ü
1. ščąŔ»ćň║ô (Knowledge Base)
- ÚŽľňůł´╝Ĺń╗ČŠťëńŞÇńެščąŔ»ćň║ô´╝îňůÂńŞşňîůňÉźňÉäšžŹŠľçŠíúŃÇé
2. ňłćňŁŚ (Chunking)
- Ŕ┐Öń║ŤŠľçŠíúŔóźňłćŠłÉŔőąň╣▓ň░ĆňŁŚ´╝ĆńެňŁŚń╗úŔíĘŠľçŠíúšÜäńŞÇÚâĘňłćňćůň«╣ŃÇé
3. ňÁîňůąŠĘíň×ő (Embedding Model)
- Š»ĆńެňŁŚÚÇÜŔ┐çňÁîňůąŠĘíň×őŔŻČňîľńŞ║ňÉĹÚçĆ´╝îŔ┐Öń║ŤňÉĹÚçĆŠś»ŔíĘšĄ║ŠľçŠťČňćůň«╣šÜäÚźśš╗┤ŠĽ░ŠŹ«šé╣ŃÇé
4. ňÉĹÚçĆŠĽ░ŠŹ«ň║ô (Vector Database)
- ŠëÇŠťëŔ┐Öń║ŤňÁîňůąňÉĹÚçĆŔóźňşśňéĘňťĘńŞÇńެňÉĹÚçĆŠĽ░ŠŹ«ň║ôńŞşŃÇéŔ»ąŠĽ░ŠŹ«ň║ôňîůŠőČš┤óň╝ĽŃÇüňÁîňůąŃÇüŠľçŠťČňŁŚňĺîňů⊼░ŠŹ«ŃÇé
- ňťĘŠĽ░ŠŹ«ň║ôńŞş´╝îŠčąŔ»óňÉĹÚçĆńŞÄšŤŞń╝╝ňÉĹÚçĆń╣őÚŚ┤šÜäňů│š│╗ňĆ»ń╗ąňŞ«ňŐęŠúÇš┤óŠťÇšŤŞňů│šÜäń┐íŠü»ŃÇé
5. ŠĆÉšĄ║ŠĘ튣┐ (Prompt Template)
- ŠĆÉšĄ║ŠĘ튣┐Šá╣ŠŹ«ŠčąŔ»óŠĆÉńżŤńŞŐńŞőŠľç´╝îŠî皥║ÚťÇŔŽüňŤ×šşöšÜäÚŚ«Úóśń╗ąňĆŐšŤŞňů│šÜäńŞŐńŞőŠľçń┐íŠü»ŃÇé
6. Llama-3.2ŠĘíň×ő (Llama-3.2 LLM)
- Llama-3.2ňĄžŔ»şŔĘÇŠĘíň×őŠá╣ŠŹ«ŠĆÉšĄ║ŠĘ튣┐šö芳ÉňôŹň║öŃÇéŔ┐ÖńŞÇŔ┐çšĘőňîůŠőČń╗ÄŠĆÉšĄ║ńŞşŔÄĚňĆľńŞŐńŞőŠľç´╝îň╣Âňč║ń║ÄŠşĄšö芳ɚŤŞň║öšşöŠíłŃÇé
7. šöĘŠłĚšĽîÚŁó (User Interface)
- ŠťÇš╗łšÜäňôŹň║öÚÇÜŔ┐çšöĘŠłĚšĽîÚŁóŔ┐öňŤ×š╗ÖšöĘŠłĚŃÇéńżőňŽé´╝îšöĘŠłĚňĆ»ń╗ąÚÇÜŔ┐çŠÄąňĆúÔÇťChatWithYourCode!ÔÇŁŔ┐ŤŔíîŠĆÉÚŚ«ň╣ŠĹŠöŠťÇš╗łšşöŠíłŃÇé
ŠÇ╗š╗ô
ŠŹ«https://t.co/St5O59mmxtňłćŠ×É´╝îŔ»ąŠÁüšĘőŔ»Žš╗ćŔ»┤ŠśÄń║ćňŽéńŻĽň░抾çŠíúňłćňŁŚň╣ÂňşśňéĘńŞ║ňÁîňůąňÉĹÚçĆ´╝îÚÇÜŔ┐çňÉĹÚçĆŠĽ░ŠŹ«ň║ôŔ┐ŤŔíîÚźśŠĽłŠúÇš┤ó´╝îšäÂňÉÄňłęšöĘLlama-3.2ŠĘíň×őšö芳ÉŔ笚äÂŔ»şŔĘÇňôŹň║öŃÇéŔ┐ÖšžŹŠľ╣Š│ĽńŞŹń╗ůŠĆÉÚźśń║ćń┐íŠü»ŠúÇš┤óšÜäňçćší«ŠÇž´╝îŔ┐śŔ⯊ĆÉńżŤŠŤ┤ŠÖ║ŔâŻňĺîńŞŐńŞőŠľçšŤŞňů│šÜäšşöŠíł´╝îńŻ┐ňżŚšöĘŠłĚńŻôڬ┤ňŐáŠÁüšĽůňĺîÚźśŠĽłŃÇé