
GPTDAOCN-e/acc on Nostr: и§Јй”ҒжңәеҷЁеӯҰд№ з®—жі•зҡ„жҪңеҠӣпјҡж·ұе…ҘзҗҶи§Ји¶…еҸӮж•°и°ғдјҳ ...
и§Јй”ҒжңәеҷЁеӯҰд№ з®—жі•зҡ„жҪңеҠӣпјҡж·ұе…ҘзҗҶи§Ји¶…еҸӮж•°и°ғдјҳ
иҝҷеј еӣҫиЎЁеұ•зӨәдәҶдә”з§Қеёёи§ҒжңәеҷЁеӯҰд№ з®—жі•зҡ„и¶…еҸӮж•°еҸҠе…¶еҜ№еә”зҡ„и§Ҷи§үиЎЁзӨәгҖӮд»ҘдёӢжҳҜиҜҰз»Ҷи§ЈиҜ»пјҡ
1. зәҝжҖ§еӣһеҪ’ (Linear Regression)
- иЎЁзӨәпјҡйҖҡиҝҮжӢҹеҗҲдёҖжқЎзӣҙзәҝжқҘйў„жөӢиҝһз»ӯеҸҳйҮҸгҖӮ
- и¶…еҸӮж•°пјҡ
- Regularization parameterпјҡз”ЁдәҺRidge/LassoеӣһеҪ’зҡ„жӯЈеҲҷеҢ–еҸӮж•°пјҲеҰӮalphaпјүпјҢеё®еҠ©йҳІжӯўиҝҮжӢҹеҗҲгҖӮ
2. йҖ»иҫ‘еӣһеҪ’ (Logistic Regression)
- иЎЁзӨәпјҡдҪҝз”ЁSеҪўжӣІзәҝжқҘйў„жөӢдәҢеҲҶзұ»й—®йўҳгҖӮ
- и¶…еҸӮж•°пјҡ
- CпјҡжӯЈеҲҷеҢ–ејәеәҰзҡ„еҖ’ж•°пјҢиҫғе°Ҹзҡ„еҖјжҢҮе®ҡжӣҙејәзҡ„жӯЈеҲҷеҢ–гҖӮ
- PenaltyпјҡжӯЈеҲҷеҢ–зұ»еһӢпјҲL1жҲ–L2пјүгҖӮ
3. еҶізӯ–ж ‘ (Decision Tree)
- иЎЁзӨәпјҡйҖҡиҝҮиҠӮзӮ№еҲҶеүІж•°жҚ®йӣҶжқҘеҒҡеҮәеҶізӯ–гҖӮ
- и¶…еҸӮж•°пјҡ
- Max_depthпјҡж ‘зҡ„жңҖеӨ§ж·ұеәҰгҖӮ
- Min_samples_splitпјҡеҶ…йғЁиҠӮзӮ№еҶҚеҲ’еҲҶжүҖйңҖзҡ„жңҖе°Ҹж ·жң¬ж•°гҖӮ
- Min_samples_leafпјҡеҸ¶иҠӮзӮ№жүҖйңҖзҡ„жңҖе°Ҹж ·жң¬ж•°гҖӮ
- Criterionпјҡз”ЁдәҺиЎЎйҮҸеҲҶеүІиҙЁйҮҸзҡ„жҢҮж ҮпјҲеҰӮGiniжҲ–EntropyпјүгҖӮ
4. Kиҝ‘йӮ»з®—жі• (K-Nearest Neighbors)
- иЎЁзӨәпјҡеҹәдәҺи·қзҰ»еәҰйҮҸиҝӣиЎҢеҲҶзұ»гҖӮ
- и¶…еҸӮж•°пјҡ
- n_neighborsпјҡз”ЁдәҺеҲҶзұ»зҡ„йӮ»еұ…ж•°йҮҸгҖӮ
- Weightsпјҡйў„жөӢж—¶еҗ„йӮ»еұ…зҡ„жқғйҮҚеҲҶй…Қж–№ејҸгҖӮ
- Metricпјҡз”ЁдәҺи·қзҰ»и®Ўз®—зҡ„ж–№жі•гҖӮ
5. ж”ҜжҢҒеҗ‘йҮҸжңә (Support Vector Machines)
- иЎЁзӨәпјҡжүҫеҲ°жңҖдҪіеҲҶеүІи¶…е№ійқўд»ҘеҢәеҲҶдёҚеҗҢзұ»еҲ«гҖӮ
- и¶…еҸӮж•°пјҡ
- CпјҡиҜҜе·®йЎ№жғ©зҪҡзі»ж•°пјҢжҺ§еҲ¶й—ҙйҡ”еӨ§е°Ҹе’ҢиҜҜе·®жқғиЎЎгҖӮ
- Kernelпјҡз”ЁдәҺжҳ е°„иҫ“е…Ҙж•°жҚ®еҲ°й«ҳз»ҙз©әй—ҙзҡ„ж ёеҮҪж•°зұ»еһӢгҖӮ
- Gammaпјҡж ёзі»ж•°пјҢеҪұе“ҚжЁЎеһӢеӨҚжқӮжҖ§пјҲдё»иҰҒз”ЁдәҺRBFж ёпјүгҖӮ
- DegreeпјҡеӨҡйЎ№ејҸж ёеҮҪж•°дёӯзҡ„еәҰж•°гҖӮ
иҝҷдәӣи¶…еҸӮж•°еңЁжЁЎеһӢи®ӯз»ғиҝҮзЁӢдёӯиө·еҲ°и°ғиҠӮдҪңз”ЁпјҢеҪұе“ҚжЁЎеһӢжҖ§иғҪе’ҢжіӣеҢ–иғҪеҠӣгҖӮйҖүжӢ©е’Ңи°ғж•ҙеҗҲйҖӮзҡ„и¶…еҸӮж•°жҳҜдјҳеҢ–жңәеҷЁеӯҰд№ жЁЎеһӢзҡ„йҮҚиҰҒжӯҘйӘӨгҖӮ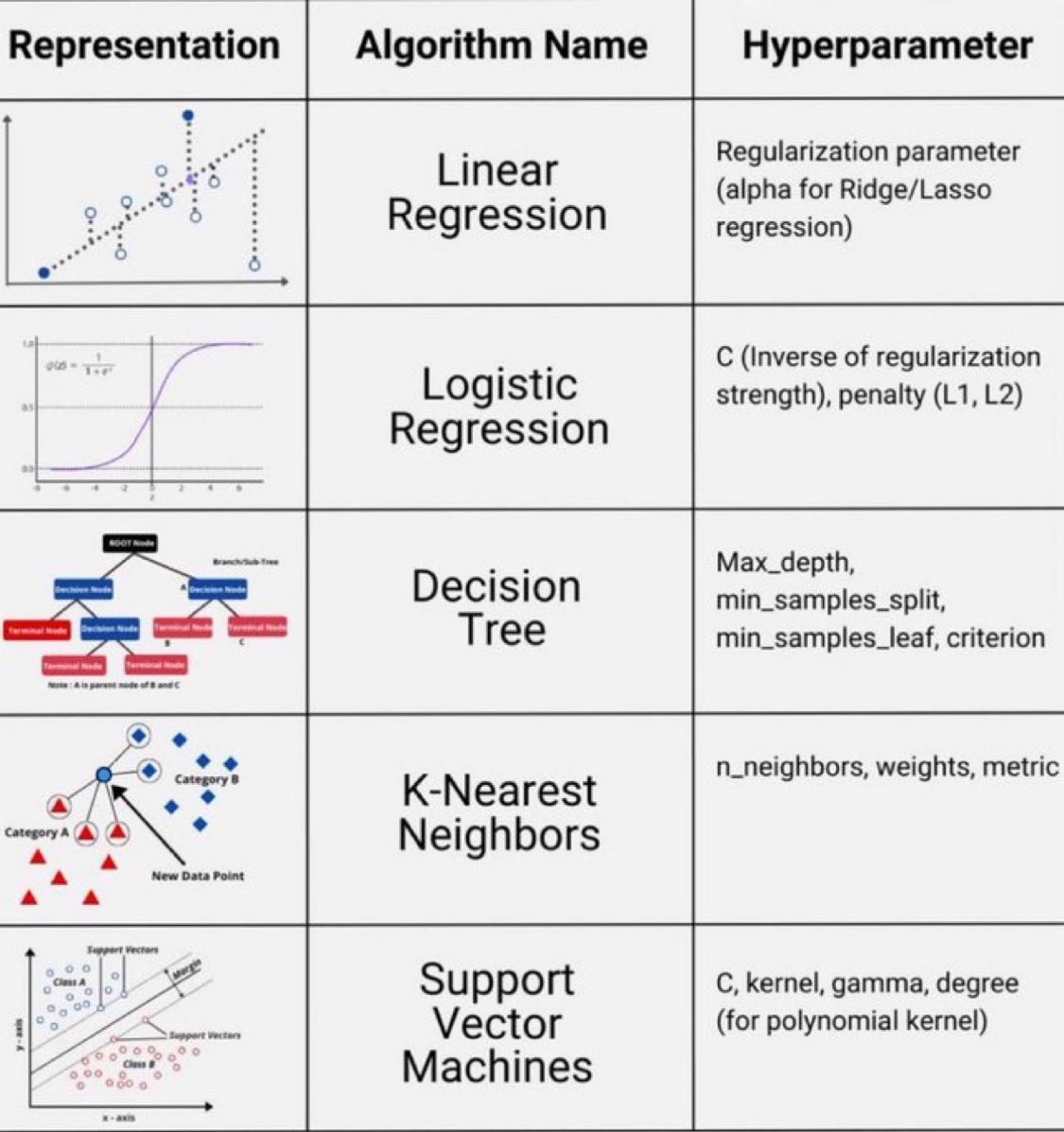
иҝҷеј еӣҫиЎЁеұ•зӨәдәҶдә”з§Қеёёи§ҒжңәеҷЁеӯҰд№ з®—жі•зҡ„и¶…еҸӮж•°еҸҠе…¶еҜ№еә”зҡ„и§Ҷи§үиЎЁзӨәгҖӮд»ҘдёӢжҳҜиҜҰз»Ҷи§ЈиҜ»пјҡ
1. зәҝжҖ§еӣһеҪ’ (Linear Regression)
- иЎЁзӨәпјҡйҖҡиҝҮжӢҹеҗҲдёҖжқЎзӣҙзәҝжқҘйў„жөӢиҝһз»ӯеҸҳйҮҸгҖӮ
- и¶…еҸӮж•°пјҡ
- Regularization parameterпјҡз”ЁдәҺRidge/LassoеӣһеҪ’зҡ„жӯЈеҲҷеҢ–еҸӮж•°пјҲеҰӮalphaпјүпјҢеё®еҠ©йҳІжӯўиҝҮжӢҹеҗҲгҖӮ
2. йҖ»иҫ‘еӣһеҪ’ (Logistic Regression)
- иЎЁзӨәпјҡдҪҝз”ЁSеҪўжӣІзәҝжқҘйў„жөӢдәҢеҲҶзұ»й—®йўҳгҖӮ
- и¶…еҸӮж•°пјҡ
- CпјҡжӯЈеҲҷеҢ–ејәеәҰзҡ„еҖ’ж•°пјҢиҫғе°Ҹзҡ„еҖјжҢҮе®ҡжӣҙејәзҡ„жӯЈеҲҷеҢ–гҖӮ
- PenaltyпјҡжӯЈеҲҷеҢ–зұ»еһӢпјҲL1жҲ–L2пјүгҖӮ
3. еҶізӯ–ж ‘ (Decision Tree)
- иЎЁзӨәпјҡйҖҡиҝҮиҠӮзӮ№еҲҶеүІж•°жҚ®йӣҶжқҘеҒҡеҮәеҶізӯ–гҖӮ
- и¶…еҸӮж•°пјҡ
- Max_depthпјҡж ‘зҡ„жңҖеӨ§ж·ұеәҰгҖӮ
- Min_samples_splitпјҡеҶ…йғЁиҠӮзӮ№еҶҚеҲ’еҲҶжүҖйңҖзҡ„жңҖе°Ҹж ·жң¬ж•°гҖӮ
- Min_samples_leafпјҡеҸ¶иҠӮзӮ№жүҖйңҖзҡ„жңҖе°Ҹж ·жң¬ж•°гҖӮ
- Criterionпјҡз”ЁдәҺиЎЎйҮҸеҲҶеүІиҙЁйҮҸзҡ„жҢҮж ҮпјҲеҰӮGiniжҲ–EntropyпјүгҖӮ
4. Kиҝ‘йӮ»з®—жі• (K-Nearest Neighbors)
- иЎЁзӨәпјҡеҹәдәҺи·қзҰ»еәҰйҮҸиҝӣиЎҢеҲҶзұ»гҖӮ
- и¶…еҸӮж•°пјҡ
- n_neighborsпјҡз”ЁдәҺеҲҶзұ»зҡ„йӮ»еұ…ж•°йҮҸгҖӮ
- Weightsпјҡйў„жөӢж—¶еҗ„йӮ»еұ…зҡ„жқғйҮҚеҲҶй…Қж–№ејҸгҖӮ
- Metricпјҡз”ЁдәҺи·қзҰ»и®Ўз®—зҡ„ж–№жі•гҖӮ
5. ж”ҜжҢҒеҗ‘йҮҸжңә (Support Vector Machines)
- иЎЁзӨәпјҡжүҫеҲ°жңҖдҪіеҲҶеүІи¶…е№ійқўд»ҘеҢәеҲҶдёҚеҗҢзұ»еҲ«гҖӮ
- и¶…еҸӮж•°пјҡ
- CпјҡиҜҜе·®йЎ№жғ©зҪҡзі»ж•°пјҢжҺ§еҲ¶й—ҙйҡ”еӨ§е°Ҹе’ҢиҜҜе·®жқғиЎЎгҖӮ
- Kernelпјҡз”ЁдәҺжҳ е°„иҫ“е…Ҙж•°жҚ®еҲ°й«ҳз»ҙз©әй—ҙзҡ„ж ёеҮҪж•°зұ»еһӢгҖӮ
- Gammaпјҡж ёзі»ж•°пјҢеҪұе“ҚжЁЎеһӢеӨҚжқӮжҖ§пјҲдё»иҰҒз”ЁдәҺRBFж ёпјүгҖӮ
- DegreeпјҡеӨҡйЎ№ејҸж ёеҮҪж•°дёӯзҡ„еәҰж•°гҖӮ
иҝҷдәӣи¶…еҸӮж•°еңЁжЁЎеһӢи®ӯз»ғиҝҮзЁӢдёӯиө·еҲ°и°ғиҠӮдҪңз”ЁпјҢеҪұе“ҚжЁЎеһӢжҖ§иғҪе’ҢжіӣеҢ–иғҪеҠӣгҖӮйҖүжӢ©е’Ңи°ғж•ҙеҗҲйҖӮзҡ„и¶…еҸӮж•°жҳҜдјҳеҢ–жңәеҷЁеӯҰд№ жЁЎеһӢзҡ„йҮҚиҰҒжӯҘйӘӨгҖӮ