
AVERAGE_GARY on Nostr: Ripped from Xitter and shared here for my nostrich homies... Thnx Murch for the great ...
Ripped from Xitter and shared here for my nostrich homies... Thnx Murch (nprofile…8cm0) for the great breakdown.
Let’s talk about Cluster Mempool!
Each of our full nodes stores unconfirmed transactions in its mempool. This cache is an important resource for the node and enables the p2p transaction relay network. By learning about and validating most transactions before a block is announced, blocks relay quickly.
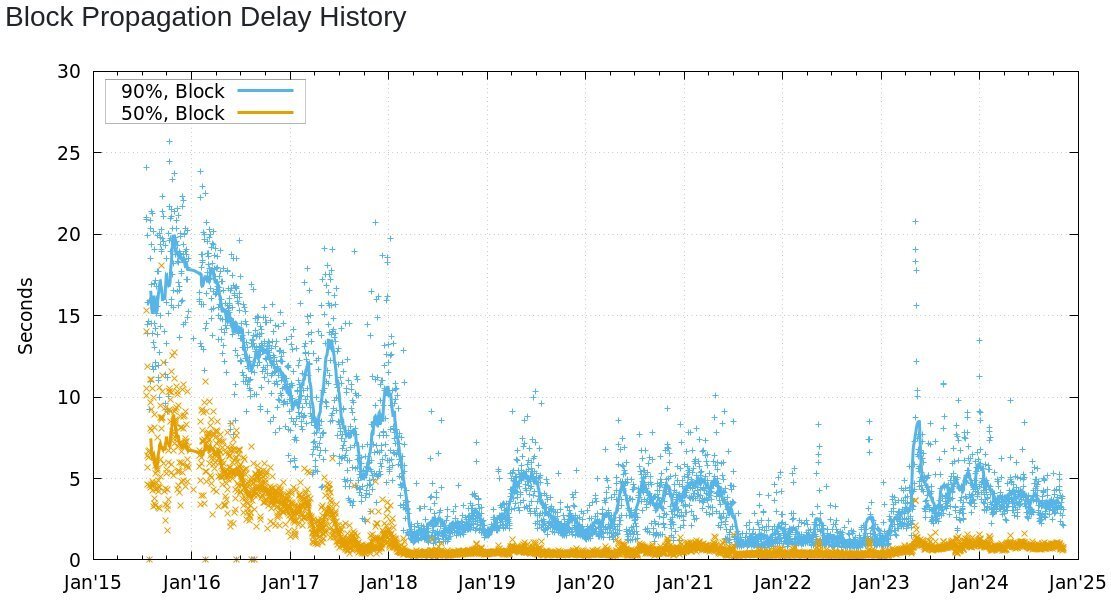
By observing which transactions first appear in the mempool and later get published in blocks, a node can unilaterally estimate the necessary feerate to make a successful bid on blockspace to get a transaction confirmed.
Nodes relaying transactions to all peers is indispensable for user privacy and censorship-resistance in the network. Quick and unfettered access to unconfirmed transactions allows anyone to build competitive block templates and permissionlessly become a miner.
Currently, Bitcoin Core tracks each transaction in the context of its ancestors. A block template is greedily assembled by picking the ancestor set with the highest ancestor set feerate into the block, updating the ancestor sets of all affected descendants, repeat.
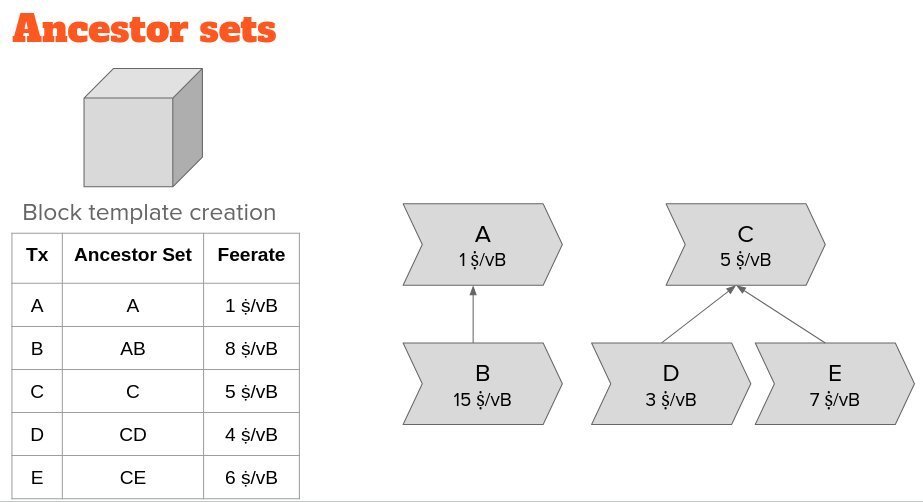
This approach has the downside that we need to update transaction data as we build the block template, and that we can only predict a transaction’s mining score (the feerate at which it will be picked into a block), after taking into account all of its relatives.
Sometimes demand for blockspace is so high that our node receives more transactions than it can cache in its limited mempool. Whenever the mempool overflows, we would like to evict the transactions that are least attractive for mining.
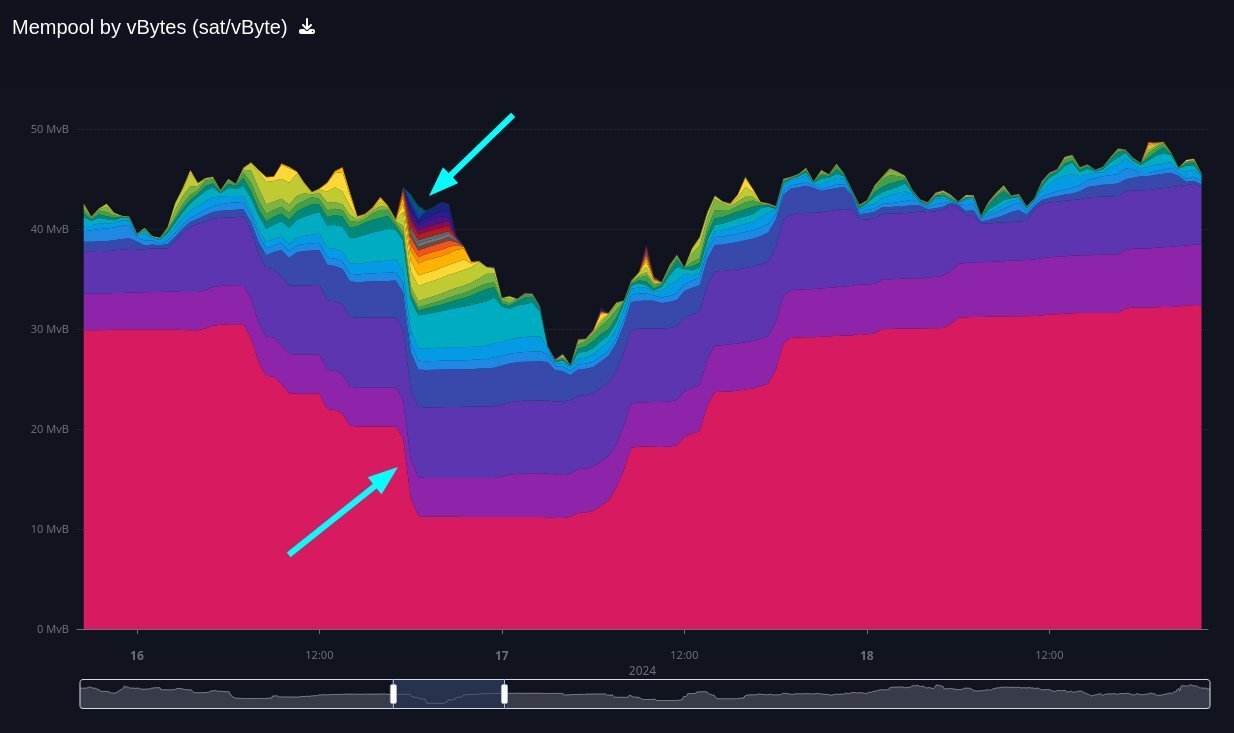
Unfortunately, the dependency of transactions on their relatives means that we can only accurately predict which transaction would be mined last, by calculating all the transactions that we would pick before it. We cannot afford this computation for each eviction.
So, instead we use a heuristic to imperfectly asses which transaction should be evicted first. We additionally track each transaction in the context of its descendant set, and use the lowest descendant set score of transactions as an indicator for eviction.
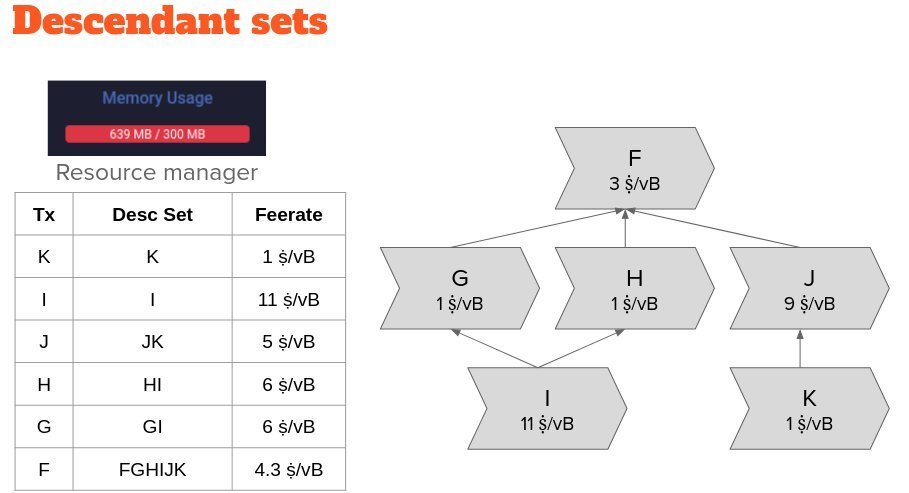
If a single transactions or a leaf transaction has the lowest descendant set feerate in our mempool, this result is accurate. However, this heuristic may fail to correctly identify the transaction that would be picked into a block template last.
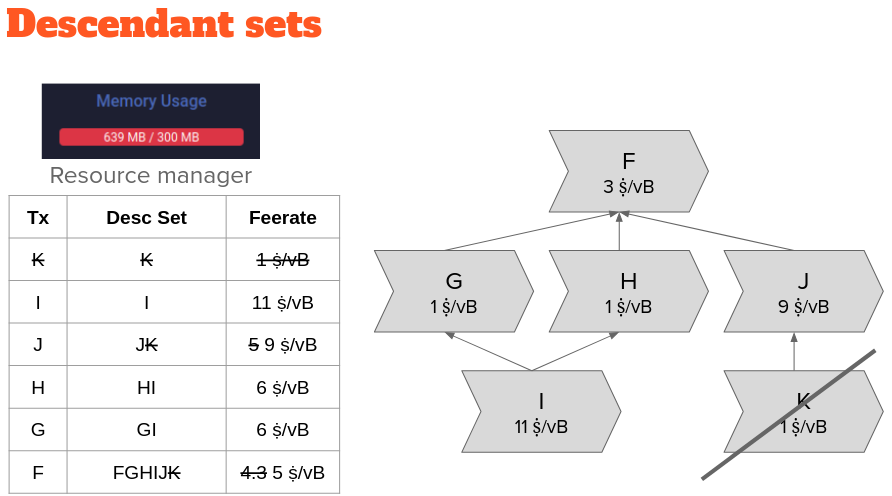
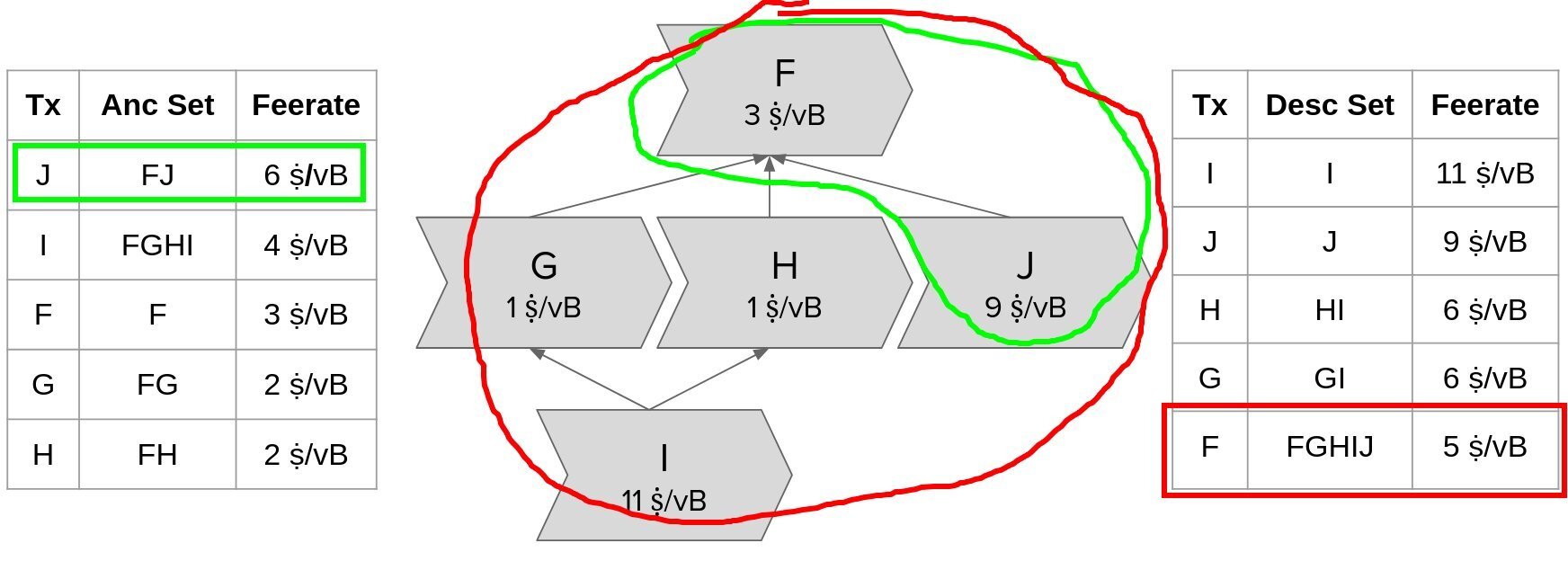
In this example transaction graph, J’s ancestor set has the highest ancestor set feerate and would be mined next with its ancestor F, but F has the lowest descendant set feerate and would be evicted with all its descendants including J.
Finally, it is well-known that the BIP125-inspired RBF rules used by Bitcoin Core do not always lead to incentive compatible replacements. We know of cases where replacements get accepted but do not improve the mempool, and cases that get rejected but would improve it.
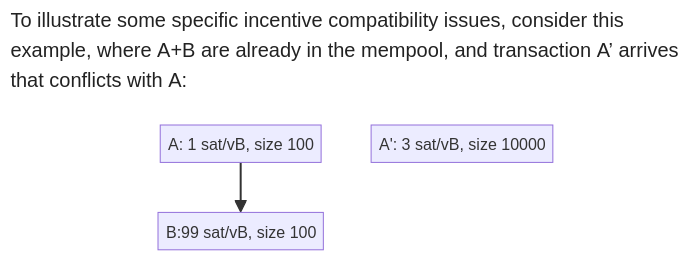
Enter the Cluster Mempool proposal (H/T to Suhas Daftuar and Pieter Wuille): What if we were able to always know the order of the entire mempool and could always read off the mining score of every transaction?

Instead of tracking each transaction in the context of its ancestor set and its descendant set, we track each transaction in the context of its _cluster_, its entire "family" of related transactions!
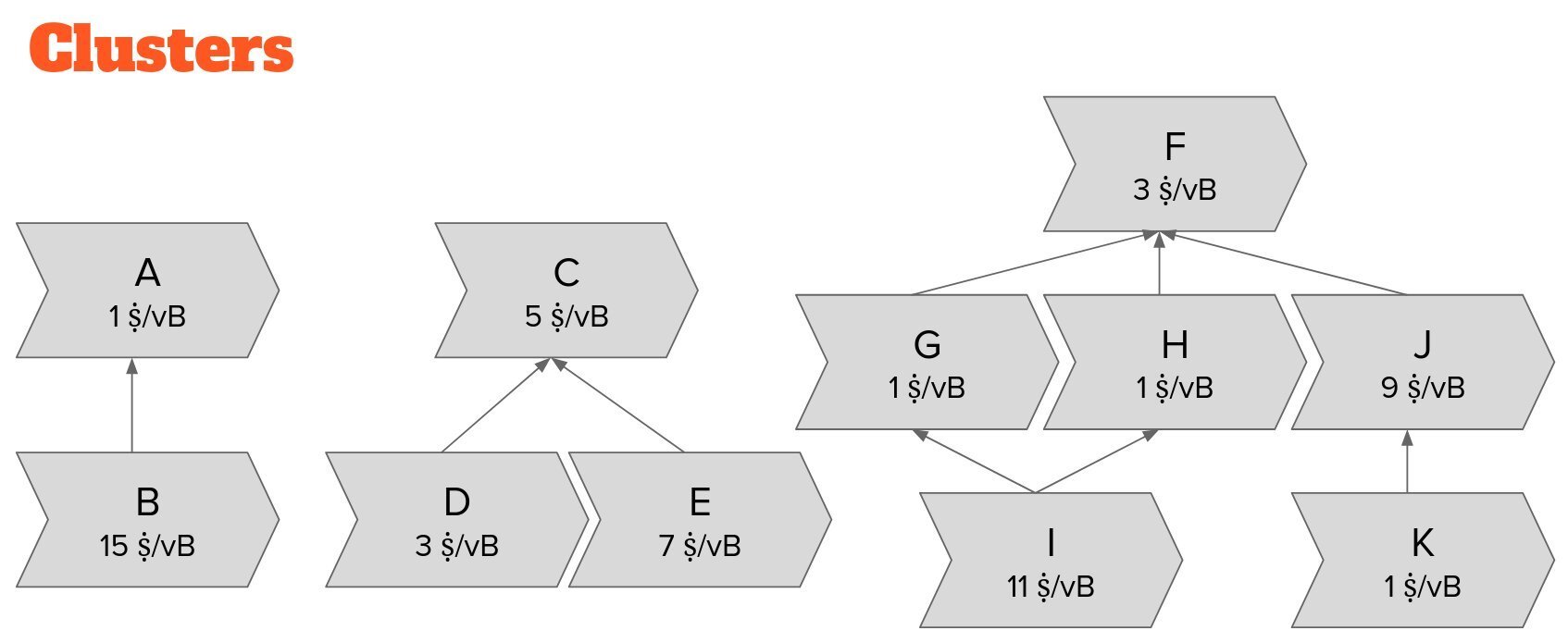
Each transaction only belongs to a single cluster. We find clusters by starting with any transaction and adding all its children and parents, and the children and parents of its children and parents, and so forth, until there is nothing left to add.
We then "linearize" each cluster: we convert the transaction graph into a list by sorting them in the order in which the cluster’s transactions would be picked into a block template.
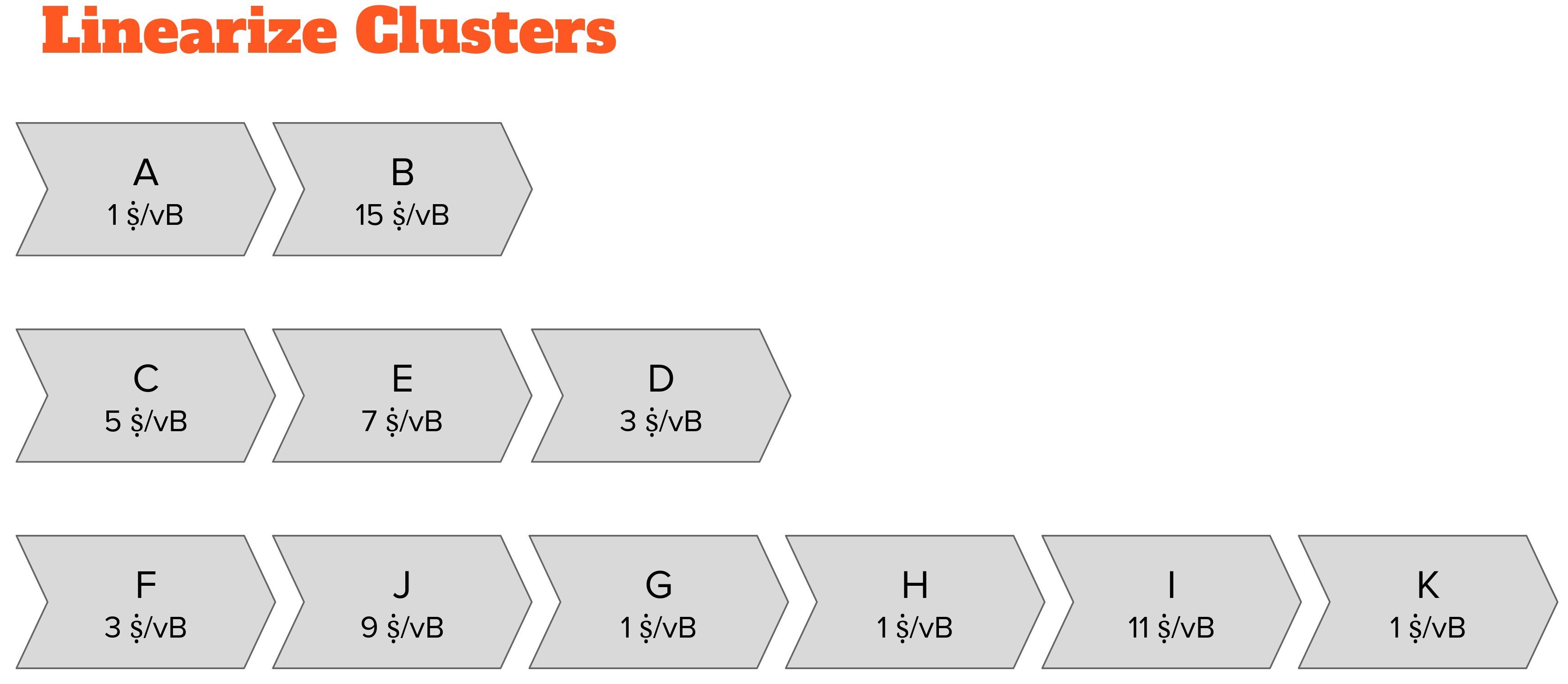
For now, you can think about a cluster linearization as running a block building algorithm on the cluster and recording the order in which the transactions get picked into the block.
Calculating the linearization of big complicated clusters can be computationally expensive.
The computational cost of operations on clusters limits their size. We will leave it at that for the moment, but if you want to learn more, @pwuille wrote a treatise on how to efficiently linearize clusters on Delving Bitcoin: https://delvingbitcoin.org/t/introduction-to-cluster-linearization/1032
Previously, we used ancestor sets to notice when e.g. a child in a CPFP constellation made it attractive to pick a package of parent and child together into our block template.

Our cluster linearization allows us to easily identify segments of transactions that will naturally be included in blocks together. Whenever higher-feerate transactions follow lower-feerate transactions, we group them together into _Chunks_.
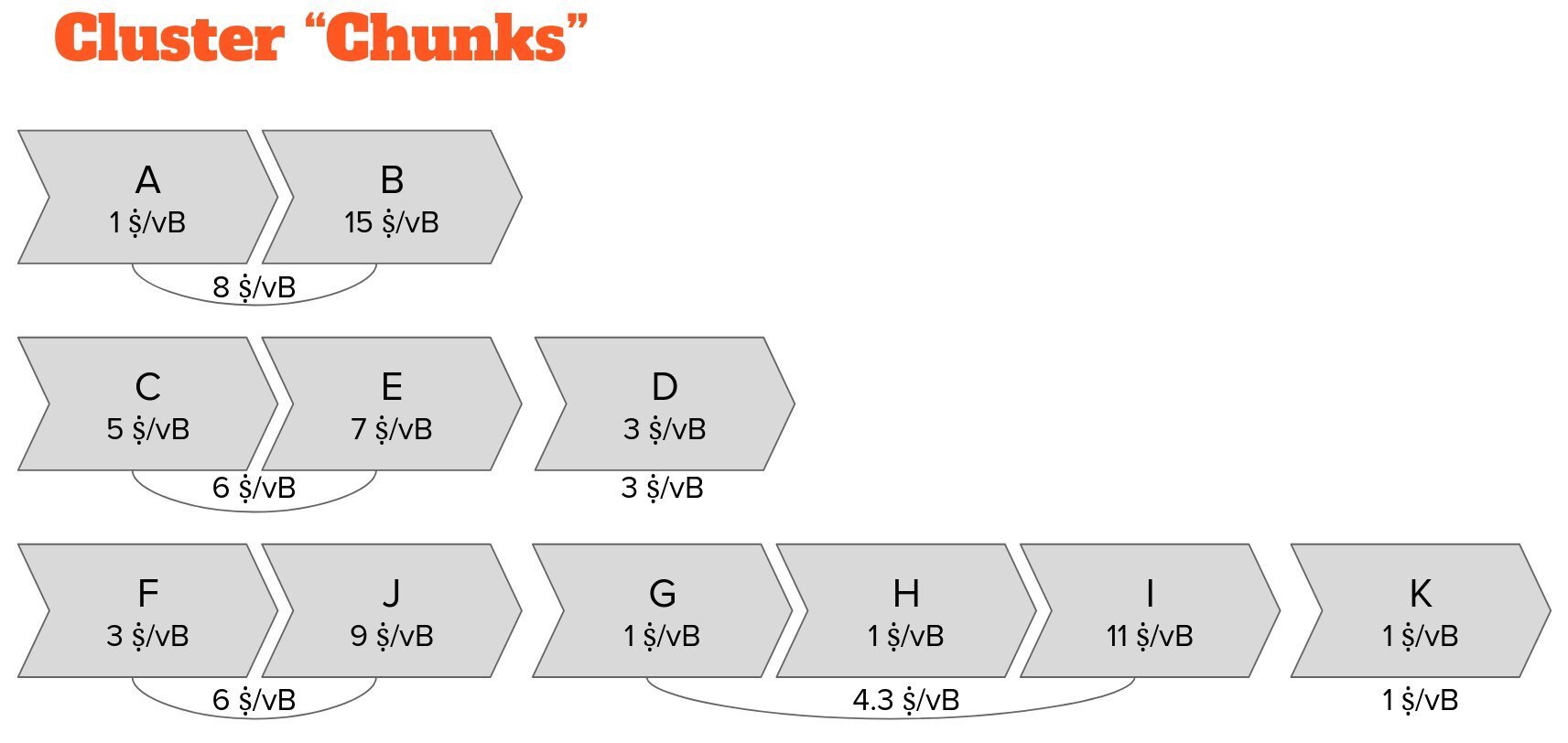
These chunks have marvelous advantages over ancestor sets: 1) Multiple children with higher feerates than their parent can naturally form a chunk with a higher chunk feerate than any child’s ancestor set feerate!
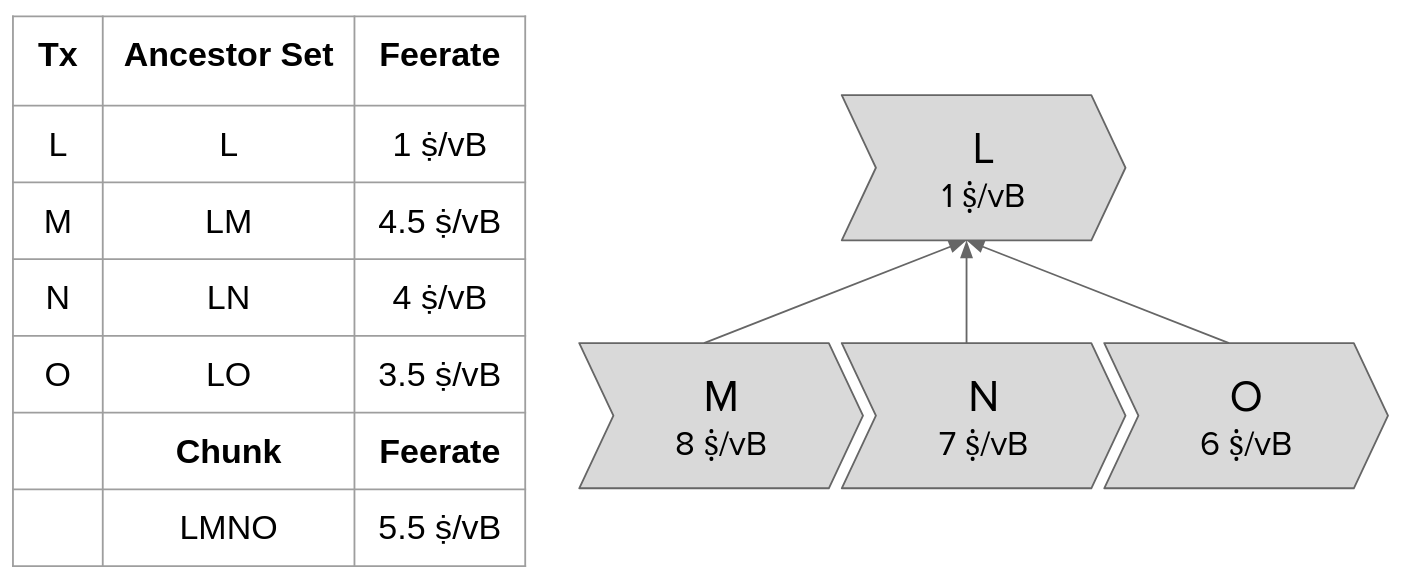
The chunk feerate only depends on the transactions in the chunk. The chunk feerate remains the same even when ancestors are picked into a block template—we can precompute the chunk feerates and read them off as the mining score of all of the chunk’s transactions!
Block building simply becomes repeatedly picking the chunk with the highest feerate across all clusters until the block template is full.
This also provides us an implicit total order of the entire mempool.
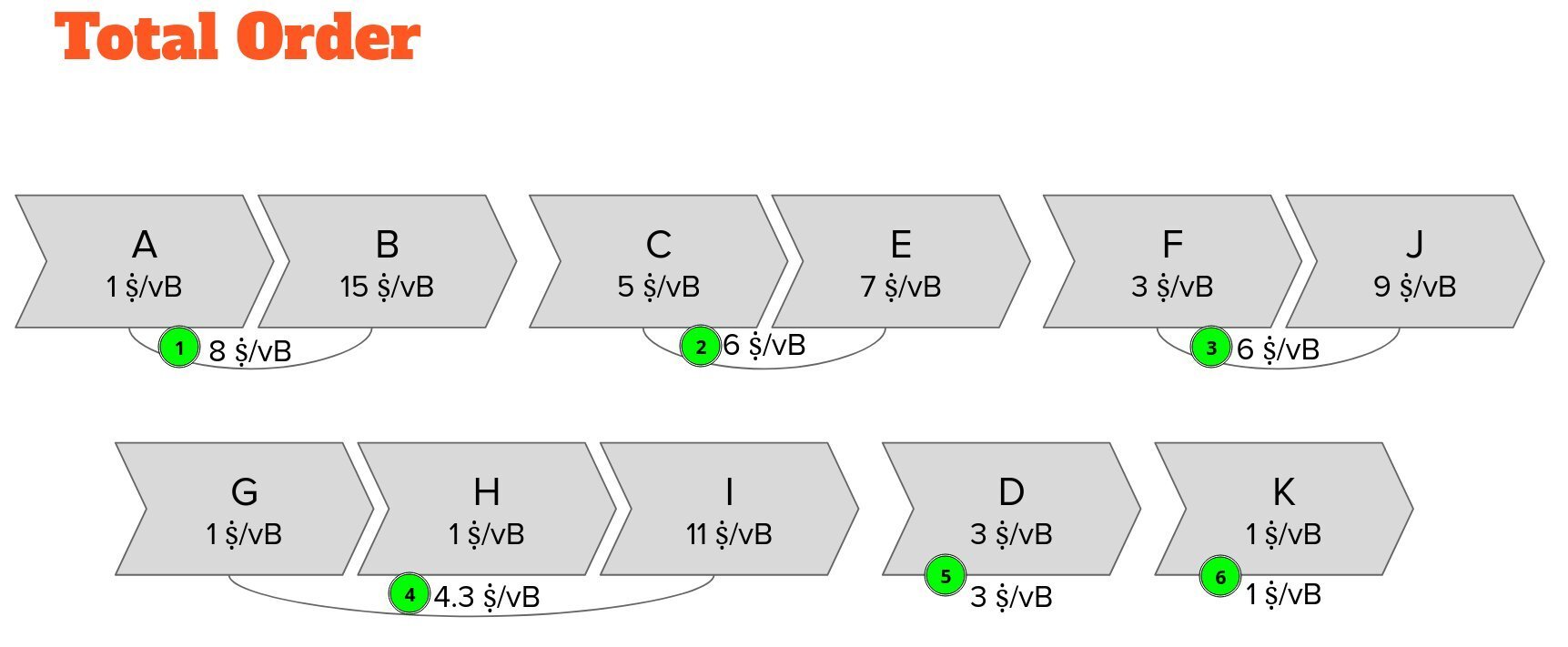
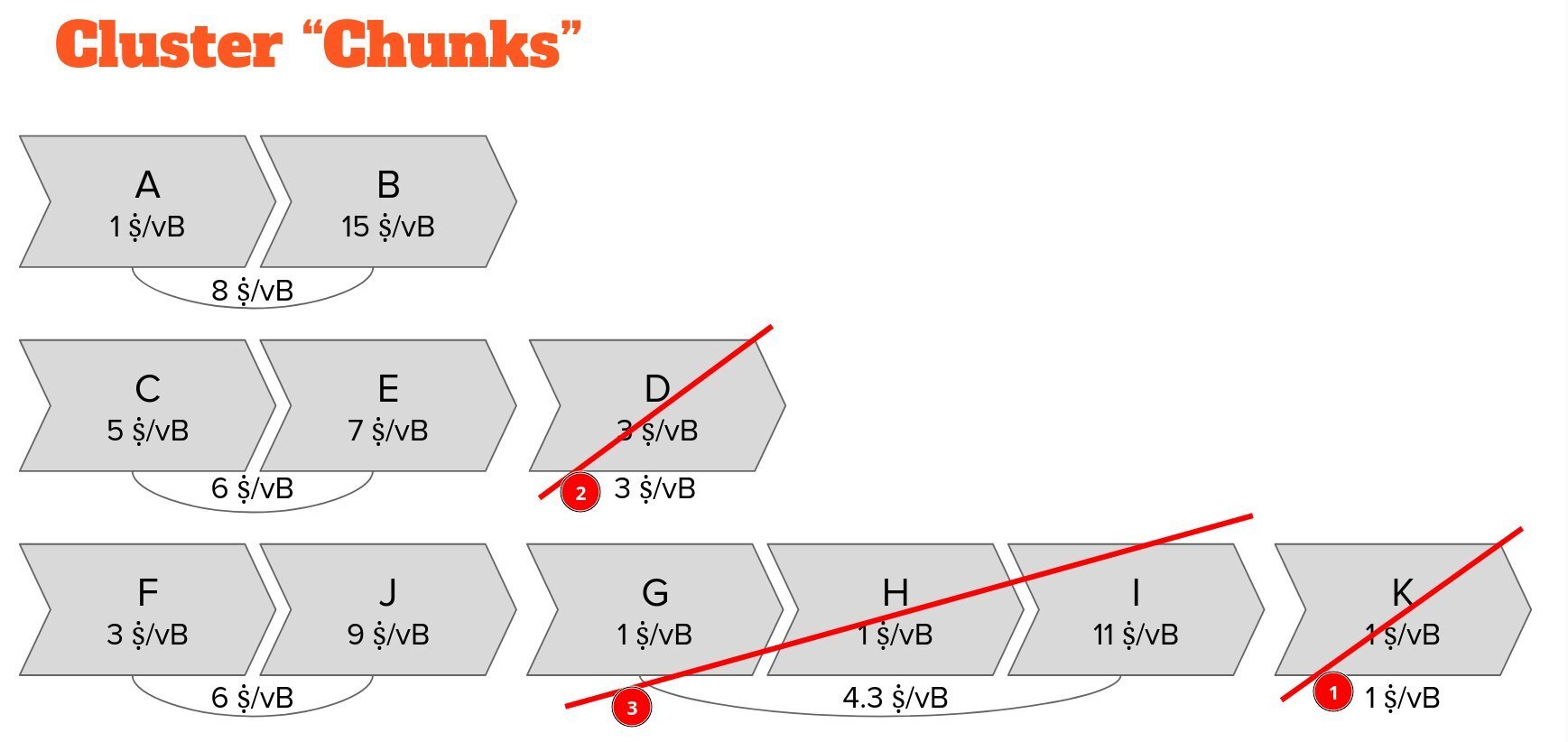
This also means that we know exactly which chunks we will mine last.
Eviction simply becomes kicking out the chunk with the lowest feerate across all clusters.
In conclusion, Cluster Mempool offers us:
• Faster block building
• Always available mining scores
• Near-optimal eviction
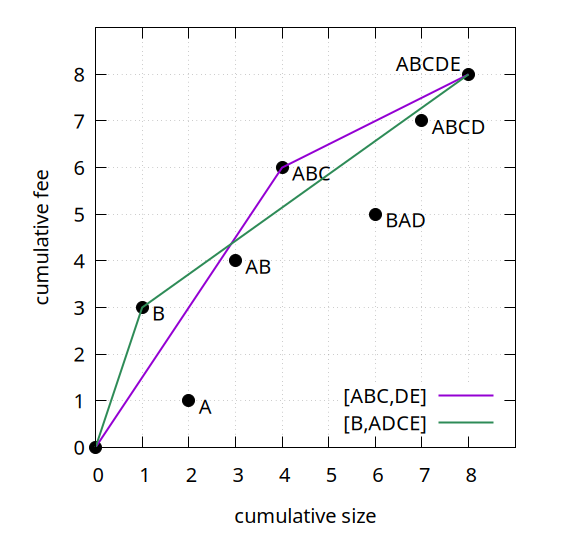
• A better framework for thinking about Package RBF via so-called feerate diagrams
at the mere cost of some pre-computation and a cluster limit.
Let’s talk about Cluster Mempool!
Each of our full nodes stores unconfirmed transactions in its mempool. This cache is an important resource for the node and enables the p2p transaction relay network. By learning about and validating most transactions before a block is announced, blocks relay quickly.
By observing which transactions first appear in the mempool and later get published in blocks, a node can unilaterally estimate the necessary feerate to make a successful bid on blockspace to get a transaction confirmed.
Nodes relaying transactions to all peers is indispensable for user privacy and censorship-resistance in the network. Quick and unfettered access to unconfirmed transactions allows anyone to build competitive block templates and permissionlessly become a miner.
Currently, Bitcoin Core tracks each transaction in the context of its ancestors. A block template is greedily assembled by picking the ancestor set with the highest ancestor set feerate into the block, updating the ancestor sets of all affected descendants, repeat.
This approach has the downside that we need to update transaction data as we build the block template, and that we can only predict a transaction’s mining score (the feerate at which it will be picked into a block), after taking into account all of its relatives.
Sometimes demand for blockspace is so high that our node receives more transactions than it can cache in its limited mempool. Whenever the mempool overflows, we would like to evict the transactions that are least attractive for mining.
Unfortunately, the dependency of transactions on their relatives means that we can only accurately predict which transaction would be mined last, by calculating all the transactions that we would pick before it. We cannot afford this computation for each eviction.
So, instead we use a heuristic to imperfectly asses which transaction should be evicted first. We additionally track each transaction in the context of its descendant set, and use the lowest descendant set score of transactions as an indicator for eviction.
If a single transactions or a leaf transaction has the lowest descendant set feerate in our mempool, this result is accurate. However, this heuristic may fail to correctly identify the transaction that would be picked into a block template last.
In this example transaction graph, J’s ancestor set has the highest ancestor set feerate and would be mined next with its ancestor F, but F has the lowest descendant set feerate and would be evicted with all its descendants including J.
Finally, it is well-known that the BIP125-inspired RBF rules used by Bitcoin Core do not always lead to incentive compatible replacements. We know of cases where replacements get accepted but do not improve the mempool, and cases that get rejected but would improve it.
Enter the Cluster Mempool proposal (H/T to Suhas Daftuar and Pieter Wuille): What if we were able to always know the order of the entire mempool and could always read off the mining score of every transaction?
Instead of tracking each transaction in the context of its ancestor set and its descendant set, we track each transaction in the context of its _cluster_, its entire "family" of related transactions!
Each transaction only belongs to a single cluster. We find clusters by starting with any transaction and adding all its children and parents, and the children and parents of its children and parents, and so forth, until there is nothing left to add.
We then "linearize" each cluster: we convert the transaction graph into a list by sorting them in the order in which the cluster’s transactions would be picked into a block template.
For now, you can think about a cluster linearization as running a block building algorithm on the cluster and recording the order in which the transactions get picked into the block.
Calculating the linearization of big complicated clusters can be computationally expensive.
The computational cost of operations on clusters limits their size. We will leave it at that for the moment, but if you want to learn more, @pwuille wrote a treatise on how to efficiently linearize clusters on Delving Bitcoin: https://delvingbitcoin.org/t/introduction-to-cluster-linearization/1032
Previously, we used ancestor sets to notice when e.g. a child in a CPFP constellation made it attractive to pick a package of parent and child together into our block template.
Our cluster linearization allows us to easily identify segments of transactions that will naturally be included in blocks together. Whenever higher-feerate transactions follow lower-feerate transactions, we group them together into _Chunks_.
These chunks have marvelous advantages over ancestor sets: 1) Multiple children with higher feerates than their parent can naturally form a chunk with a higher chunk feerate than any child’s ancestor set feerate!
The chunk feerate only depends on the transactions in the chunk. The chunk feerate remains the same even when ancestors are picked into a block template—we can precompute the chunk feerates and read them off as the mining score of all of the chunk’s transactions!
Block building simply becomes repeatedly picking the chunk with the highest feerate across all clusters until the block template is full.
This also provides us an implicit total order of the entire mempool.
This also means that we know exactly which chunks we will mine last.
Eviction simply becomes kicking out the chunk with the lowest feerate across all clusters.
In conclusion, Cluster Mempool offers us:
• Faster block building
• Always available mining scores
• Near-optimal eviction
• A better framework for thinking about Package RBF via so-called feerate diagrams
at the mere cost of some pre-computation and a cluster limit.